在大规模软件中,使用SIMD指令重写memcpy/memcmp等函数是否有意义?
如果有意义,为什么GCC不会默认生成这些库函数的SIMD指令呢?
此外,是否还有其他函数可以通过SIMD进行改进?
在大规模软件中,使用SIMD指令重写memcpy/memcmp等函数是否有意义?
如果有意义,为什么GCC不会默认生成这些库函数的SIMD指令呢?
此外,是否还有其他函数可以通过SIMD进行改进?
memcpy调用都是针对数千字节的。你可能会在循环中有一个memcpy调用,它只有约20个字节,并且还有其他处理。 (2)现代CPU核心不仅限于处理来自单个线程的指令,这就是我提到超线程的原因。 (3)当读取预取被流水线化时,DRAM延迟就不那么重要了,只有吞吐量才是关键。 (4)即使DRAM吞吐量正在拖累代码,也最好高效地执行复制操作,因为CPU可以在同样的时间内完成工作,并且功耗更低(例如,动态降低时钟频率)。 - Ben Voigtmemchr?Glibc有手写汇编版本的memchr / strchr / memmove等函数,适用于i386和x86-64(以及大多数其他ISA),对于大缓冲区非常出色,并且许多还具有良好的小缓冲区策略。 (通过动态链接器符号解析进行运行时分派,因此即使在没有使用-mavx2编译的二进制文件中,它也可以在兼容CPU上使用AVX2)。你能获得的主要优势是,如果你知道你的缓冲区已经对齐并且/或者至少有16个字节长,那么你就可以避免分支来选择策略。 - Peter Cordesvpcmpeqb,然后将它们全部合并为一个向量,以节省 vpmovmskb 和 test 操作码,每 2 个缓存行循环一次分支。 - Peter Cordes这没有意义。如果你的编译器能够发出SIMD指令,那么它应该隐式地为memcpy / memcmp /类似内部函数发出这些指令。
您可能需要明确指示GCC使用例如-msse -msse2发出SSE操作码;一些GCC默认情况下不启用它们。此外,如果您不告诉GCC进行优化(即-o2),它甚至不会尝试发出快速代码。
像这样使用SIMD操作码对内存工作可以产生巨大的性能影响,因为它们还包括缓存预取和其他DMA提示,这些提示对于优化总线访问非常重要。但这并不意味着您需要手动发出它们;即使大多数编译器通常都很糟糕,但我使用过的每个编译器至少都处理了基本CRT内存函数的操作。
基本数学函数也可以从将编译器设置为SSE模式中受益。您可以轻松获得8倍的加速,只需告诉编译器使用SSE操作码而不是可怕的旧x87 FPU。
memcpy最有可能被正确优化。许多其他来自<string.h>和<memory.h>的函数也极大地受益,但编译器并没有广泛优化它们。 - Ben Voigtrepne scasb strlen,或者在-O2级别下内联了一个复杂的32位一次的位操作,它没有利用SSE2的任何优势。该程序完全依赖于strlen处理大缓冲区的性能,因此调用glibc的优化版本对它来说是一个巨大的胜利。库和内联之间存在很大的区别。 - Peter Cordes这可能并不重要。CPU的速度比内存带宽快得多,而编译器运行时库提供的memcpy等实现可能已经足够好了。在“大规模”软件中,性能主要受到内存复制的影响是不太可能的(很可能是受到I/O的影响)。
要获得真正的内存复制性能提升,一些系统具有专门的DMA实现,可用于从内存复制到内存。如果需要显著提高性能,硬件是获得性能提升的途径。
memcpy 实现,它使用SIMD指令来实现高吞吐量的memcpy操作。
https://git.dpdk.org/dpdk/tree/lib/eal/x86/include/rte_memcpy.h
英特尔声称,在OpenvSwitch中,SIMD-memcpy的性能比普通memcpy提高了22%。
来自英特尔网页:
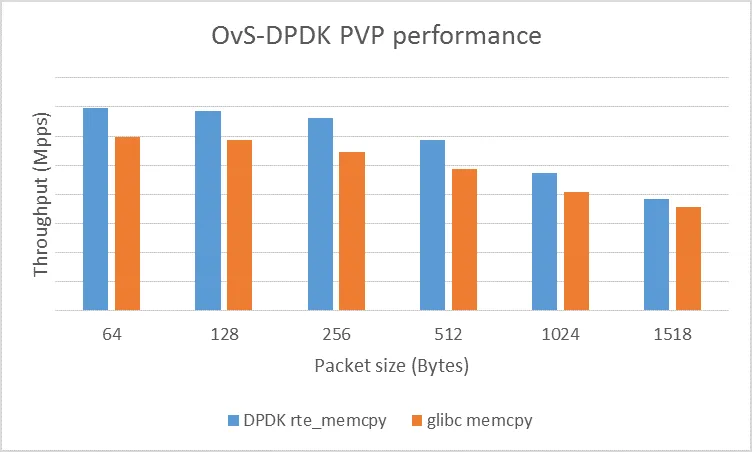
memcpy实际上是SSE内置函数的最坏情况,因为SSE不能用于边缘情况。那些编译器是否会为strlen和memchr发出SIMD代码? - Ben Voigt