首先,我不建议使用内置函数 - 它们不可移植(在同一架构的编译器之间)。
使用内部函数,GCC优化SSE内部函数,生成更加优化的代码。您可以查看汇编代码,并了解如何充分利用SSE。
内部函数很容易使用 - 就像普通函数调用:
#include <immintrin.h> // portable to all x86 compilers
int main()
{
__m128 vector1 = _mm_set_ps(4.0, 3.0, 2.0, 1.0); // high element first, opposite of C array order. Use _mm_setr_ps if you want "little endian" element order in the source.
__m128 vector2 = _mm_set_ps(7.0, 8.0, 9.0, 0.0);
__m128 sum = _mm_add_ps(vector1, vector2); // result = vector1 + vector 2
vector1 = _mm_shuffle_ps(vector1, vector1, _MM_SHUFFLE(0,1,2,3));
// vector1 is now (1, 2, 3, 4) (above shuffle reversed it)
return 0;
}
使用_mm_load_ps或_mm_loadu_ps从数组中加载数据。
当然,还有更多选项,SSE非常强大,我认为相对容易学习。
另请参见https://stackoverflow.com/tags/sse/info获取一些指南链接。
3
鉴于你需要资源:
使用C++实现SSE的实用指南:很好地概述了如何有效地使用SSE,并提供了示例。
编译器内置函数的MSDN列表:为您所有需要的内置函数提供全面的参考。虽然这是MSDN网站,但几乎所有列在此处的内置函数都得到了GCC和ICC的支持。
Christopher Wright的SSE页面:快速查看SSE操作码的含义。我猜Intel Manual也可以发挥同样的作用,但这个更快。
最好使用内置函数编写大部分代码,但要检查编译器输出的objdump以确保它生成了高效的代码。 SIMD代码生成仍然是一项相当新的技术,在某些情况下编译器可能会出错。
步骤1:手动编写一些汇编代码
我建议您在学习时首先尝试手动编写自己的汇编代码,以便查看并控制程序中正在发生的情况。
然后问题变成如何观察程序中正在发生的事情,答案是:
- GDB
- 使用C标准库来
print和assert事物
自己使用C标准库需要一点工作,但并不多。例如,在我的Linux测试设置中,我已经很好地完成了这项工作:
使用这些辅助程序,我开始尝试基础知识,例如:
- 将数据从内存加载到/从SSE寄存器存储
- 加法整数和不同大小的浮点数
- 断言结果是否符合预期
addpd.S
#include <lkmc.h>
LKMC_PROLOGUE
.data
.align 16
addps_input0: .float 1.5, 2.5, 3.5, 4.5
addps_input1: .float 5.5, 6.5, 7.5, 8.5
addps_expect: .float 7.0, 9.0, 11.0, 13.0
addpd_input0: .double 1.5, 2.5
addpd_input1: .double 5.5, 6.5
addpd_expect: .double 7.0, 9.0
.bss
.align 16
output: .skip 16
.text
/* 4x 32-bit */
movaps addps_input0, %xmm0
movaps addps_input1, %xmm1
addps %xmm1, %xmm0
movaps %xmm0, output
LKMC_ASSERT_MEMCMP(output, addps_expect, $0x10)
/* 2x 64-bit */
movaps addpd_input0, %xmm0
movaps addpd_input1, %xmm1
addpd %xmm1, %xmm0
movaps %xmm0, output
LKMC_ASSERT_MEMCMP(output, addpd_expect, $0x10)
LKMC_EPILOGUE
paddq.S
#include <lkmc.h>
LKMC_PROLOGUE
.data
.align 16
input0: .long 0xF1F1F1F1, 0xF2F2F2F2, 0xF3F3F3F3, 0xF4F4F4F4
input1: .long 0x12121212, 0x13131313, 0x14141414, 0x15151515
paddb_expect: .long 0x03030303, 0x05050505, 0x07070707, 0x09090909
paddw_expect: .long 0x04030403, 0x06050605, 0x08070807, 0x0A090A09
paddd_expect: .long 0x04040403, 0x06060605, 0x08080807, 0x0A0A0A09
paddq_expect: .long 0x04040403, 0x06060606, 0x08080807, 0x0A0A0A0A
.bss
.align 16
output: .skip 16
.text
movaps input1, %xmm1
/* 16x 8bit */
movaps input0, %xmm0
paddb %xmm1, %xmm0
movaps %xmm0, output
LKMC_ASSERT_MEMCMP(output, paddb_expect, $0x10)
/* 8x 16-bit */
movaps input0, %xmm0
paddw %xmm1, %xmm0
movaps %xmm0, output
LKMC_ASSERT_MEMCMP(output, paddw_expect, $0x10)
/* 4x 32-bit */
movaps input0, %xmm0
paddd %xmm1, %xmm0
movaps %xmm0, output
LKMC_ASSERT_MEMCMP(output, paddd_expect, $0x10)
/* 2x 64-bit */
movaps input0, %xmm0
paddq %xmm1, %xmm0
movaps %xmm0, output
LKMC_ASSERT_MEMCMP(output, paddq_expect, $0x10)
LKMC_EPILOGUE
步骤2:编写一些内置函数
然而,对于生产代码,您可能希望使用预先存在的内置函数,而不是原始汇编,如此提到的那样:https://dev59.com/znM_5IYBdhLWcg3waSX9#1390802
现在,我尝试将先前的示例转换为使用内置函数的等效C代码。
addpq.c
#include <assert.h>
#include <string.h>
#include <x86intrin.h>
float global_input0[] __attribute__((aligned(16))) = {1.5f, 2.5f, 3.5f, 4.5f};
float global_input1[] __attribute__((aligned(16))) = {5.5f, 6.5f, 7.5f, 8.5f};
float global_output[4] __attribute__((aligned(16)));
float global_expected[] __attribute__((aligned(16))) = {7.0f, 9.0f, 11.0f, 13.0f};
int main(void) {
/* 32-bit add (addps). */
{
__m128 input0 = _mm_set_ps(1.5f, 2.5f, 3.5f, 4.5f);
__m128 input1 = _mm_set_ps(5.5f, 6.5f, 7.5f, 8.5f);
__m128 output = _mm_add_ps(input0, input1);
/* _mm_extract_ps returns int instead of float:
* * https://dev59.com/Rm035IYBdhLWcg3wQtsg
* * https://dev59.com/bE7Sa4cB1Zd3GeqP57Ut
* so we must use instead: _MM_EXTRACT_FLOAT
*/
float f;
_MM_EXTRACT_FLOAT(f, output, 3);
assert(f == 7.0f);
_MM_EXTRACT_FLOAT(f, output, 2);
assert(f == 9.0f);
_MM_EXTRACT_FLOAT(f, output, 1);
assert(f == 11.0f);
_MM_EXTRACT_FLOAT(f, output, 0);
assert(f == 13.0f);
/* And we also have _mm_cvtss_f32 + _mm_shuffle_ps, */
assert(_mm_cvtss_f32(output) == 13.0f);
assert(_mm_cvtss_f32(_mm_shuffle_ps(output, output, 1)) == 11.0f);
assert(_mm_cvtss_f32(_mm_shuffle_ps(output, output, 2)) == 9.0f);
assert(_mm_cvtss_f32(_mm_shuffle_ps(output, output, 3)) == 7.0f);
}
/* Now from memory. */
{
__m128 *input0 = (__m128 *)global_input0;
__m128 *input1 = (__m128 *)global_input1;
_mm_store_ps(global_output, _mm_add_ps(*input0, *input1));
assert(!memcmp(global_output, global_expected, sizeof(global_output)));
}
/* 64-bit add (addpd). */
{
__m128d input0 = _mm_set_pd(1.5, 2.5);
__m128d input1 = _mm_set_pd(5.5, 6.5);
__m128d output = _mm_add_pd(input0, input1);
/* OK, and this is how we get the doubles out:
* with _mm_cvtsd_f64 + _mm_unpackhi_pd
* https://dev59.com/2XfZa4cB1Zd3GeqPX_Kg
*/
assert(_mm_cvtsd_f64(output) == 9.0);
assert(_mm_cvtsd_f64(_mm_unpackhi_pd(output, output)) == 7.0);
}
return 0;
}
paddq.c
#include <assert.h>
#include <inttypes.h>
#include <string.h>
#include <x86intrin.h>
uint32_t global_input0[] __attribute__((aligned(16))) = {1, 2, 3, 4};
uint32_t global_input1[] __attribute__((aligned(16))) = {5, 6, 7, 8};
uint32_t global_output[4] __attribute__((aligned(16)));
uint32_t global_expected[] __attribute__((aligned(16))) = {6, 8, 10, 12};
int main(void) {
/* 32-bit add hello world. */
{
__m128i input0 = _mm_set_epi32(1, 2, 3, 4);
__m128i input1 = _mm_set_epi32(5, 6, 7, 8);
__m128i output = _mm_add_epi32(input0, input1);
/* _mm_extract_epi32 mentioned at:
* https://dev59.com/UWjWa4cB1Zd3GeqPsZ9I#56404421 */
assert(_mm_extract_epi32(output, 3) == 6);
assert(_mm_extract_epi32(output, 2) == 8);
assert(_mm_extract_epi32(output, 1) == 10);
assert(_mm_extract_epi32(output, 0) == 12);
}
/* Now from memory. */
{
__m128i *input0 = (__m128i *)global_input0;
__m128i *input1 = (__m128i *)global_input1;
_mm_store_si128((__m128i *)global_output, _mm_add_epi32(*input0, *input1));
assert(!memcmp(global_output, global_expected, sizeof(global_output)));
}
/* Now a bunch of other sizes. */
{
__m128i input0 = _mm_set_epi32(0xF1F1F1F1, 0xF2F2F2F2, 0xF3F3F3F3, 0xF4F4F4F4);
__m128i input1 = _mm_set_epi32(0x12121212, 0x13131313, 0x14141414, 0x15151515);
__m128i output;
/* 8-bit integers (paddb) */
output = _mm_add_epi8(input0, input1);
assert(_mm_extract_epi32(output, 3) == 0x03030303);
assert(_mm_extract_epi32(output, 2) == 0x05050505);
assert(_mm_extract_epi32(output, 1) == 0x07070707);
assert(_mm_extract_epi32(output, 0) == 0x09090909);
/* 32-bit integers (paddw) */
output = _mm_add_epi16(input0, input1);
assert(_mm_extract_epi32(output, 3) == 0x04030403);
assert(_mm_extract_epi32(output, 2) == 0x06050605);
assert(_mm_extract_epi32(output, 1) == 0x08070807);
assert(_mm_extract_epi32(output, 0) == 0x0A090A09);
/* 32-bit integers (paddd) */
output = _mm_add_epi32(input0, input1);
assert(_mm_extract_epi32(output, 3) == 0x04040403);
assert(_mm_extract_epi32(output, 2) == 0x06060605);
assert(_mm_extract_epi32(output, 1) == 0x08080807);
assert(_mm_extract_epi32(output, 0) == 0x0A0A0A09);
/* 64-bit integers (paddq) */
output = _mm_add_epi64(input0, input1);
assert(_mm_extract_epi32(output, 3) == 0x04040404);
assert(_mm_extract_epi32(output, 2) == 0x06060605);
assert(_mm_extract_epi32(output, 1) == 0x08080808);
assert(_mm_extract_epi32(output, 0) == 0x0A0A0A09);
}
return 0;
步骤3:优化一些代码并进行基准测试
最终、也是最重要和最困难的一步,当然是实际使用内置函数使您的代码变快,然后对您的改进进行基准测试。
这样做可能需要您了解一些关于 x86 微架构的知识,而我自己并不懂。CPU 与 I/O 绑定可能是其中的一件事情:“CPU bound” 和 “I/O bound” 是什么意思?
如https://dev59.com/znM_5IYBdhLWcg3waSX9#12172046 所述,这几乎不可避免地涉及到阅读 Agner Fog 的文档,它似乎比 Intel 自己发布的任何文档都更好。
然而,希望步骤1和2将作为功能非性能方面的基础,让您快速了解指令在做什么。
待办事项:在此处生成一个最小的有趣的优化示例。
2
kernel_fpu_begin() / _end(),以防止Linux内核模块出现问题。LKM是最不可能使用SIMD的地方,也是最难测试的地方,因此在介绍SIMD的基础知识时,将其作为第一步似乎会让人感到困惑。 - Peter Cordeskernel_fpu_begin()。我现在为了好玩刚刚弄了一个例子在这里。 - Ciro Santilli OurBigBook.com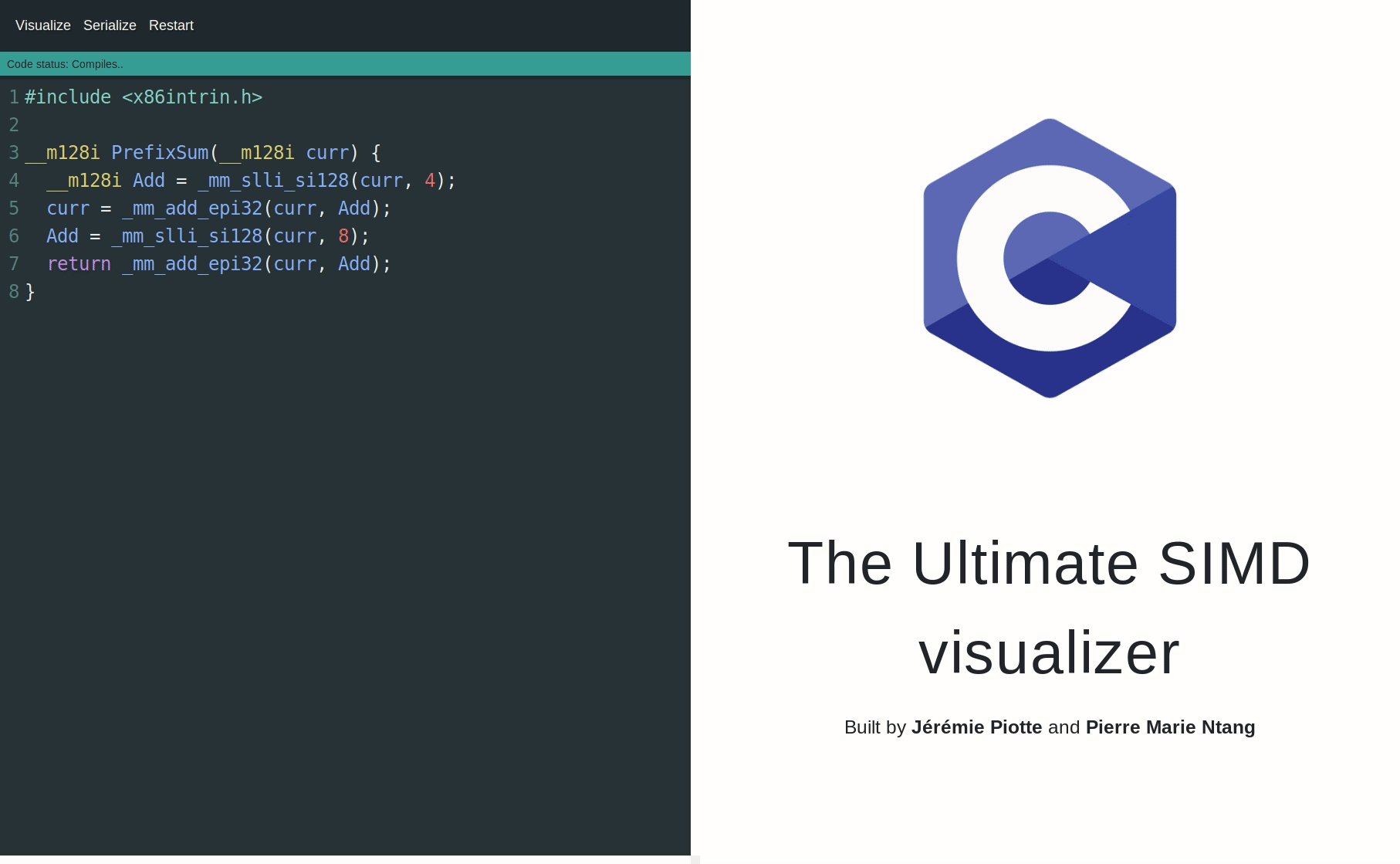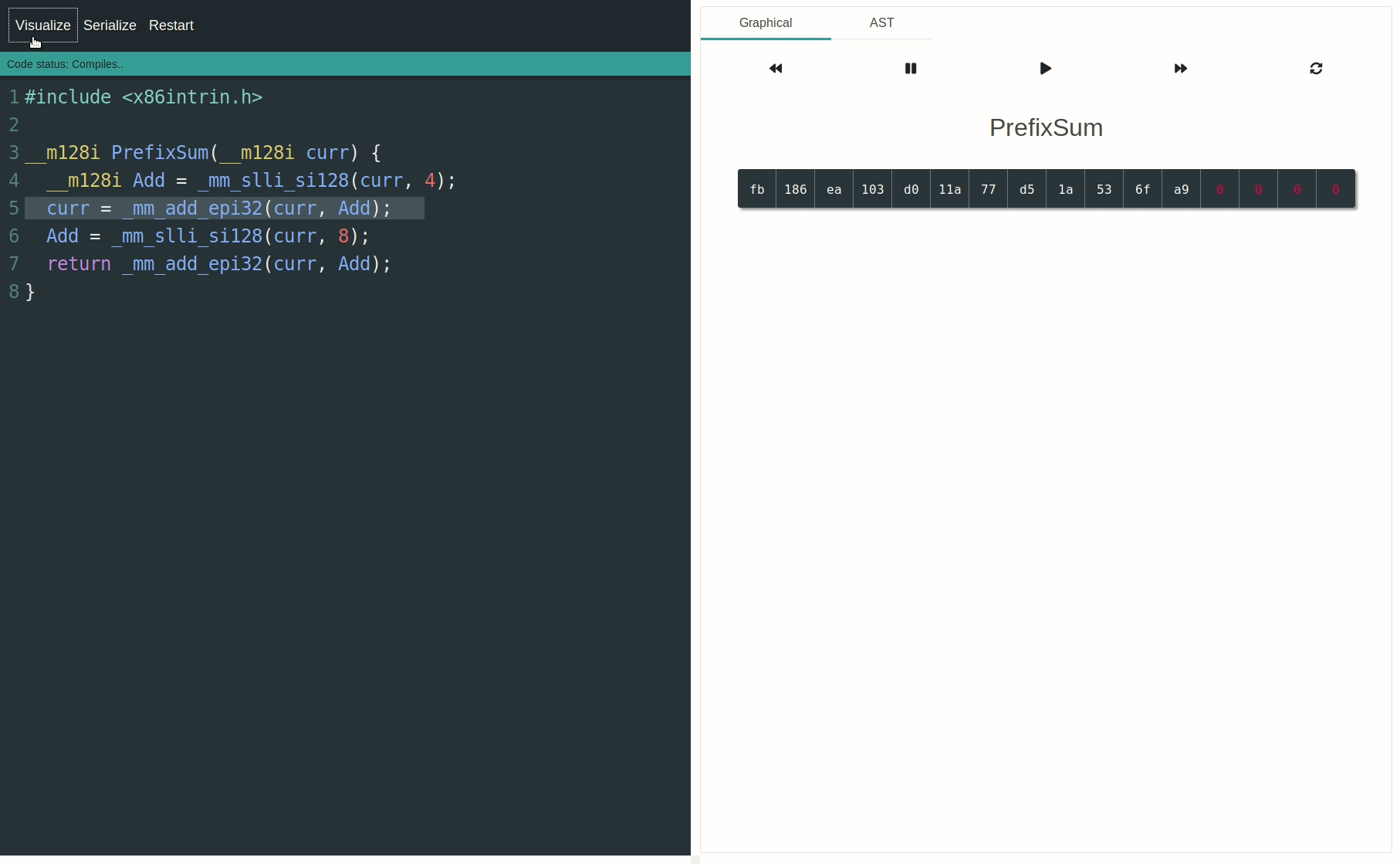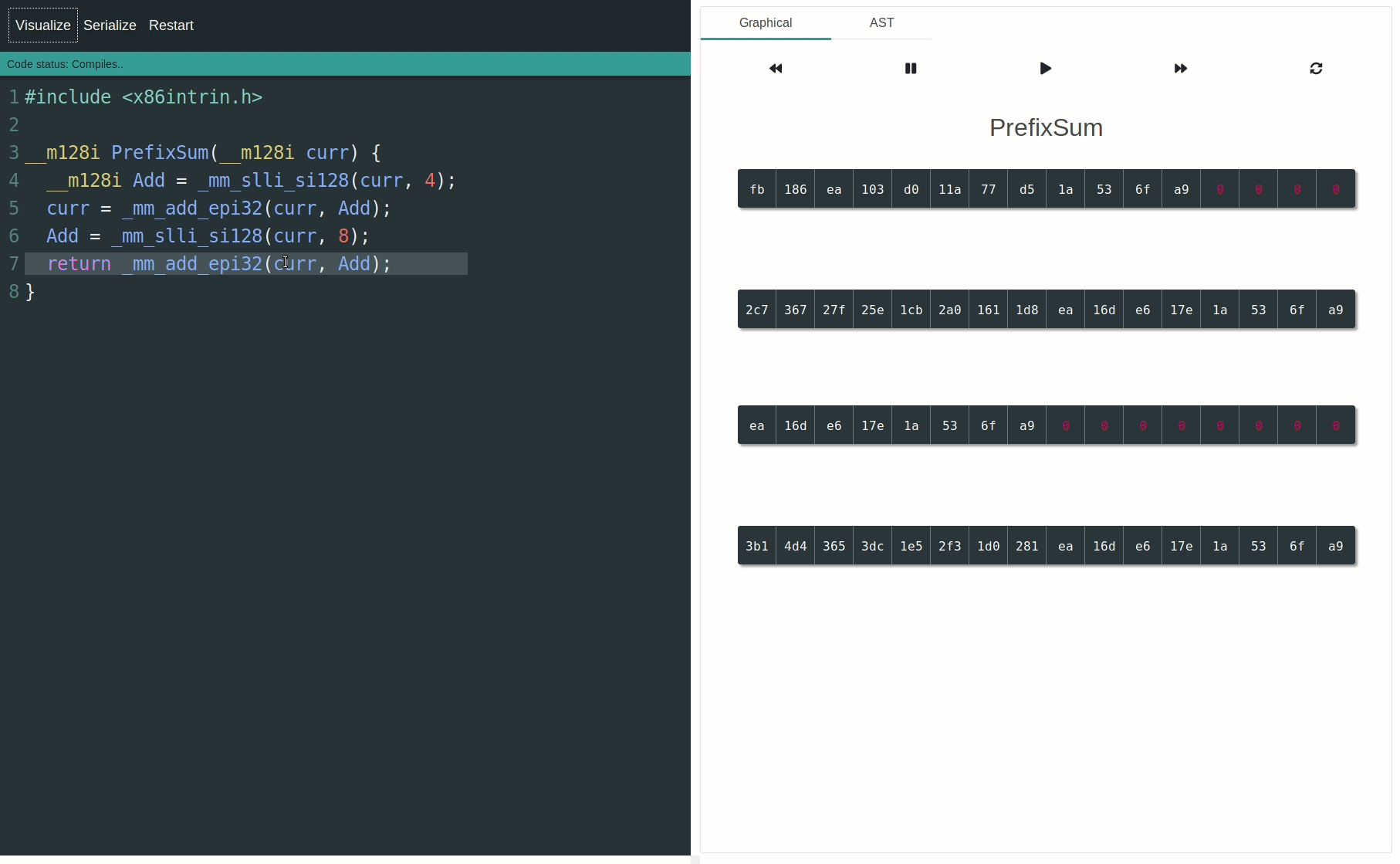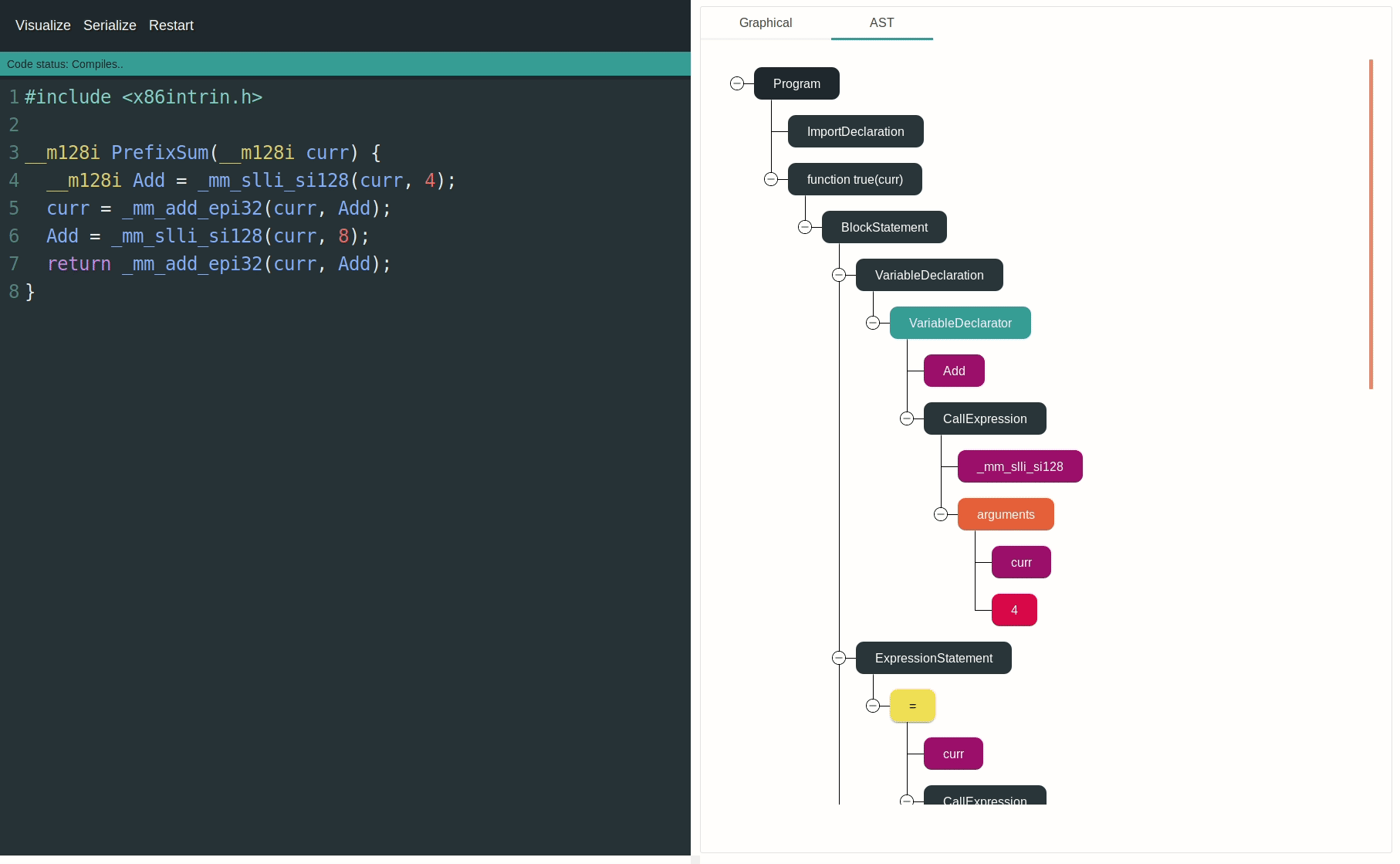
原文链接
x86intrin.h只适用于 gcc/clang (或许还有 ICC)。在 MSVC 上肯定不可用。SSE/AVX 内嵌函数的正确跨平台头文件是immintrin.h。替换xmmintrin.h是个好主意(因为它只定义了 SSE1 内嵌函数)。 - Peter Cordes