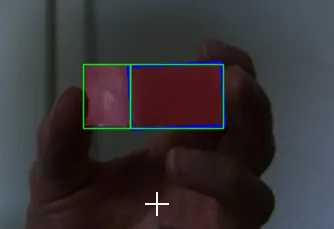
我需要什么
我目前正在开发一款增强现实游戏。游戏使用的控制器(我指的是物理输入设备)是一个单色、矩形的纸片。我需要在相机的捕捉流中检测出该矩形的位置、旋转和大小。检测应该与比例尺度无关,以及在X和Y轴上的旋转无关。
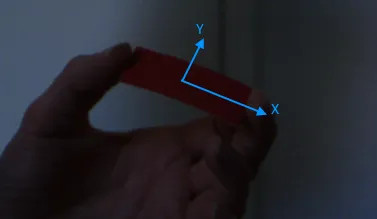
比例尺度的不变性是必需的,以防用户将纸张向相机远离或靠近。我不需要知道矩形的距离,因此比例尺度转化为大小不变性。
旋转不变性是必需的,以防用户沿其本地X和/或Y轴倾斜矩形。这样的旋转会将纸张的形状从矩形变为梯形。在这种情况下,可以使用面向对象的边界框来测量纸张的大小。
我所做的事情
一开始是校准步骤。一个窗口显示相机的视频流,用户必须点击矩形。点击后,鼠标指向的像素颜色被作为参考颜色。帧被转换到HSV颜色空间以改善颜色区分。我有6个滑块,调整每个通道的上下阈值。这些阈值用于对图像进行二值化(使用opencv的inRange函数)。
之后我对二值图像进行腐蚀和膨胀,以消除噪声和汇集附近的块(使用opencv的erode和dilate函数)。
下一步是在二值图像中找到轮廓(使用opencv的findContours函数)。这些轮廓用于检测最小定向矩形(使用opencv的minAreaRect函数)。作为最终结果,我使用面积最大的矩形。
该过程的简要总结:
- 获取一帧
- 将该帧转换为HSV格式
- 二值化(使用用户选择的颜色和滑块中的阈值)
- 应用形态学操作(腐蚀和膨胀)
- 查找轮廓
- 获取每个轮廓的最小定向边界框
- 选择其中最大的边界框作为结果
- 尺度不变性:据我所知,一些算法不支持不同尺度的对象。
- 运动预测:一些算法使用运动预测来提高性能,但我正在跟踪的对象完全随机移动,因此是不可预测的。
- 简单性:我只是在图像中寻找一个单色矩形,没有像汽车或人物追踪那样花哨。
正如你所注意到的那样,我没有利用有关纸张实际形状的知识优势,仅仅是因为我不知道如何正确地使用这些信息。
我也考虑过使用OpenCV的跟踪算法。但是有三个原因阻止了我使用它们:
这是一个 - 相对 - 不错的拍摄(经过腐蚀和膨胀后的二进制图像)

这是一个不好的拍摄

问题
如何改进一般的检测,尤其是更加抵抗光照变化?
更新
这里有一些用于测试的原始图像。
你不能只使用更厚的材料吗?
是的,我可以做到,并且已经在做了(不幸的是,我目前无法访问这些素材)。然而,问题仍然存在。即使我使用卡纸等材料,它也不像纸张那样容易弯曲,但人们仍然可以将其弯曲。
如何获取矩形的大小、旋转和位置?
OpenCV的minAreaRect函数返回一个RotatedRect对象。该对象包含我需要的所有数据。
注意
因为矩形是单色的,所以无法区分顶部和底部或左侧和右侧。这意味着旋转始终在范围[0, 180]内,这对我的目的来说完全没问题。矩形的两边比例总是w:h > 2:1。如果矩形是正方形,则旋转范围将更改为[0, 90],但这在这里可以被认为不相关。
正如评论中建议的,我将尝试直方图均衡化以减少亮度问题,并查看ORB、SURF和SIFT。
我会在进展方面进行更新。