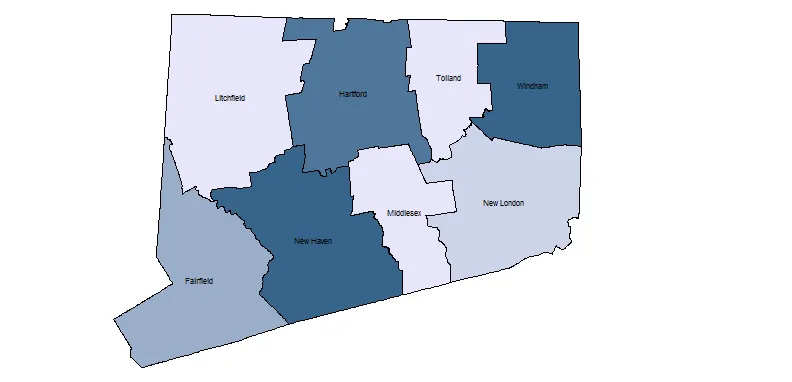
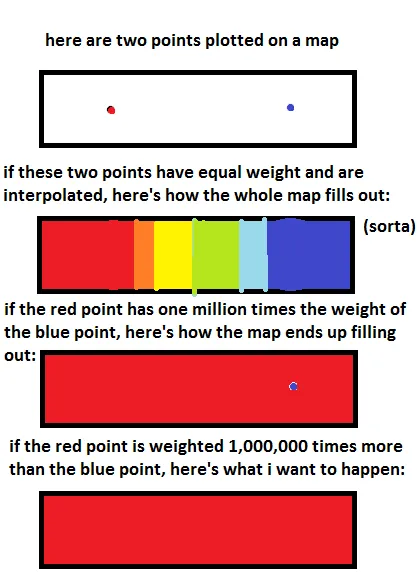
免责声明 - 我不是Krigging方面的专家。Krigging很复杂,需要对基础数据、方法和目的有很好的理解才能获得正确的结果。你可能希望尝试从GIS Stack Exchange上获取@whuber的意见或通过他的网站(
http://www.quantdec.com/quals/quals.htm))联系其他专家。
话虽如此,如果你只是想达到你所要求的视觉效果,并且不打算用于某种统计分析,我认为有一些相对简单的解决方案。
编辑:
正如您所评论的那样,尽管以下建议使用theta和smoothness参数可以使预测表面更加平滑,但它们同样适用于所有测量值,因此不能将人口密集县相对于人口较少的县的“影响范围”扩大。经过进一步考虑,我认为有两种方法可以实现这一点:通过改变协方差函数以依赖于人口密度或使用权重,就像您所做的那样。如我下面所写,您的加权方法会改变krigging函数的误差项。也就是说,它会反向缩放nugget方差。
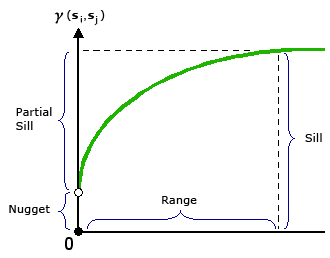
正如您在半变异图像中所看到的,小区块基本上是y截距或同一位置测量之间的误差。 权重影响小区块方差(sigma
2),即sigma
2 /权重。 因此,更大的权重意味着在小尺度距离上误差更小。 然而,这并不会改变半方差函数的形状,也不会对范围或 sill 产生太多影响。
我认为最好的解决方案是使您的协方差函数依赖于种群。 但是,我不知道如何实现,并且我没有看到任何可以执行此操作的
Krig参数。 我尝试玩定义自己的协方差函数,就像
Krig示例中一样,但只得到错误。
对不起,我无法提供更多帮助!
了解Krigging的另一个很好的资源是:
http://www.epa.gov/airtrends/specialstudies/dsisurfaces.pdf
正如我在评论中所说的那样, sill 和 nugget 值以及半方差图的范围是可以改变的,这些都会影响平滑效果。通过在调用 Krig 时指定 weights,您正在改变测量误差的方差。也就是说,在正常使用中,权重应该与测量值的准确性成比例,因此较高的权重表示更准确的测量值。但实际上这并不适用于您的数据,但它可能会给您带来所需的效果。
要改变数据插值的方式,您可以在简单的 Krig 调用中调整两个(甚至更多)参数:theta 和 smoothness。theta 调整半方差图的范围,也就是说,随着 theta 的增加,远离测量点的点对估计值的贡献越大。您的数据范围为
range <- data.frame(lon=range(ct.data$lon),lat=range(ct.data$lat))
range[2,]-range[1,]
lon lat
2 1.383717 0.6300484
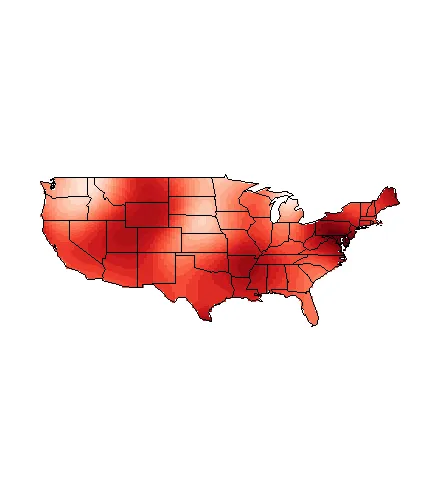
因此,您的测量点在经度上变化约1.4度,在纬度上变化约0.6度。因此,您可以尝试在该范围内指定theta值,以查看其对结果的影响。通常,较大的theta会导致更平滑,因为您从更多的值中进行预测。
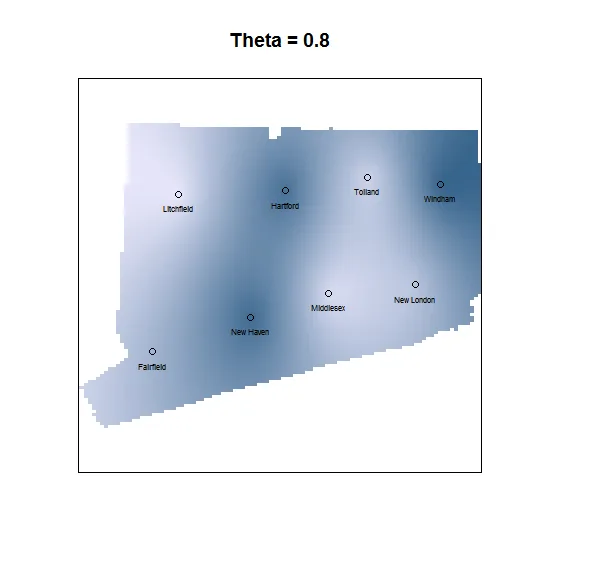
Krig.output.wt <- Krig( cbind(ct.data$lon,ct.data$lat) , ct.data$county.poverty.rate ,
weights=c( size , 1 , 1 , 1 , 1 , size , size , 1 ),Covariance="Matern", theta=.8)
r <- interpolate(ras, Krig.output.wt)
r <- mask(r, ct.map)
plot(r, col=colRamp(100) ,axes=FALSE,legend=FALSE)
title(main="Theta = 0.8", outer = FALSE)
points(cbind(ct.data$lon,ct.data$lat))
text(ct.data$lon, ct.data$lat-0.05, ct.data$NAME, cex=0.5)
给出:
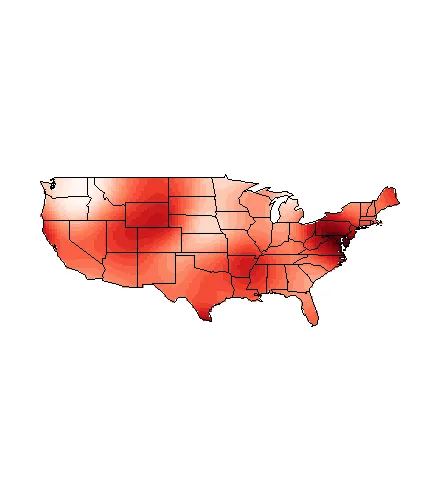
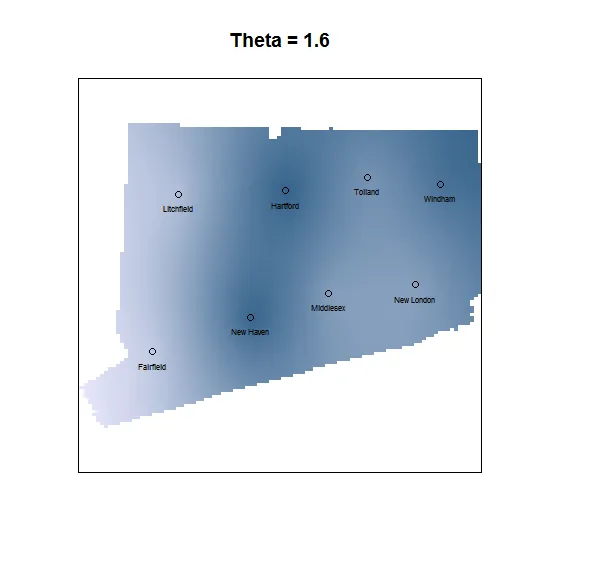
Krig.output.wt <- Krig( cbind(ct.data$lon,ct.data$lat) , ct.data$county.poverty.rate ,
weights=c( size , 1 , 1 , 1 , 1 , size , size , 1 ),Covariance="Matern", theta=1.6)
r <- interpolate(ras, Krig.output.wt)
r <- mask(r, ct.map)
plot(r, col=colRamp(100) ,axes=FALSE,legend=FALSE)
title(main="Theta = 1.6", outer = FALSE)
points(cbind(ct.data$lon,ct.data$lat))
text(ct.data$lon, ct.data$lat-0.05, ct.data$NAME, cex=0.5)
给出:
添加
smoothness 参数将改变用于平滑预测的函数顺序。默认值为0.5,导致使用二次多项式。
Krig.output.wt <- Krig( cbind(ct.data$lon,ct.data$lat) , ct.data$county.poverty.rate ,
weights=c( size , 1 , 1 , 1 , 1 , size , size , 1 ),
Covariance="Matern", smoothness = 0.6)
r <- interpolate(ras, Krig.output.wt)
r <- mask(r, ct.map)
plot(r, col=colRamp(100) ,axes=FALSE,legend=FALSE)
title(main="Theta unspecified; Smoothness = 0.6", outer = FALSE)
points(cbind(ct.data$lon,ct.data$lat))
text(ct.data$lon, ct.data$lat-0.05, ct.data$NAME, cex=0.5)
提供:

这应该给你一个起点和一些选项,但你应该查看
fields 的手册。它写得非常好,并很好地解释了参数。
此外,如果这在任何方面是定量的,我强烈建议与具有显著空间统计知识的人交谈!