
我有一组图像需要去噪以便进行OCR:
我试图从图像中读取1973年的信息。
我尝试过:
import cv2,numpy as np
img=cv2.imread('uxWbP.png',0)
img = cv2.resize(img, (0, 0), fx=2, fy=2)
copy_img=np.copy(img)
#adaptive threshold as the image has different lighting conditions in different areas
thresh = cv2.adaptiveThreshold(img, 255, cv2.ADAPTIVE_THRESH_GAUSSIAN_C, cv2.THRESH_BINARY, 21, 2)
contours, _ = cv2.findContours(thresh, cv2.RETR_TREE, cv2.CHAIN_APPROX_SIMPLE)
#kill small contours
for i_cnt, cnt in enumerate(sorted(contours, key=lambda x: cv2.boundingRect(x)[0])):
_area = cv2.contourArea(cnt)
x, y, w, h = cv2.boundingRect(cnt)
x_y_area = w * h
if 10000 < x_y_area and x_y_area < 400000:
pass
# cv2.rectangle(copy_img, (x, y), (x + w, y + h), (255, 0, 255), 2)
# cv2.putText(copy_img, str(int(x_y_area)) + ' , ' + str(w) + ' , ' + str(h), (x, y + 10), cv2.FONT_HERSHEY_SIMPLEX, 0.6, (0, 0, 255), 2)
# cv2.drawContours(copy_img, [cnt], 0, (0, 255, 0), 1)
elif 10000 > x_y_area:
#write over small contours
cv2.drawContours(thresh, [cnt], -1, 255, -1)
cv2.imshow('img',copy_img)
cv2.imshow('thresh',thresh)
cv2.waitKey(0)
这将显著改善图像,使其更清晰:
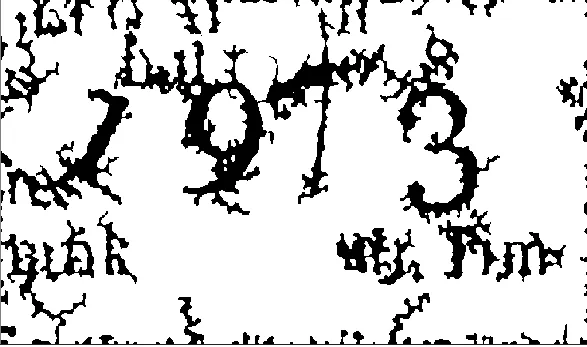
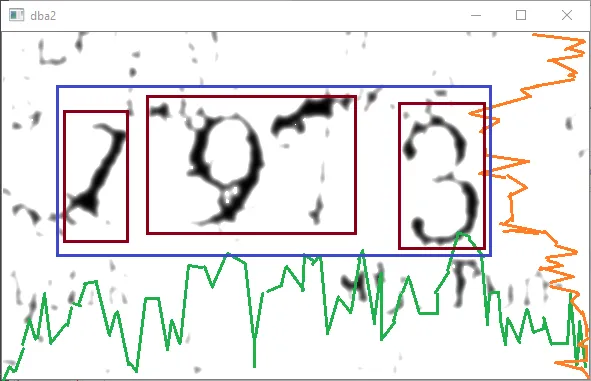
对于如何足够过滤此图像或从一开始就进行完全更改的任何建议,以便我可以运行OCR或一些ML检测脚本来检测数字。我希望拆分数字以进行检测,但也可以接受其他方法。






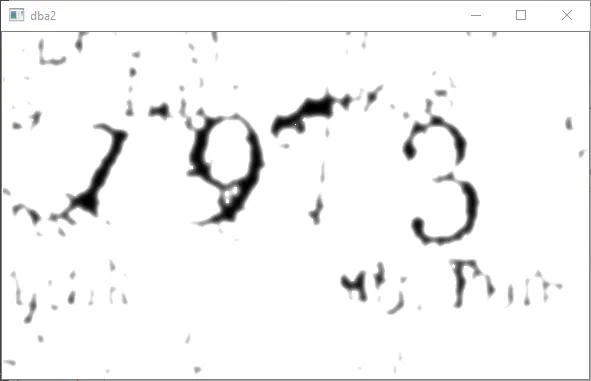
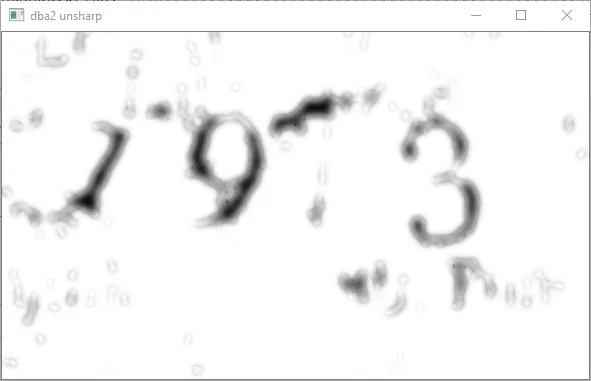{kind=link}
cv2.error: OpenCV(4.2.0) C:\projects\opencv-python\opencv\modules\imgproc\src\thresh.cpp:1647: error: (-215:Assertion failed) src.type() == CV_8UC1 in function 'cv::adaptiveThreshold'的错误提示。 - bballdave025img = cv2.imread("uxWbp.png")。然而,当我按照你的步骤进行操作并使用你的不同值之后,我仍然得到了同样的错误。抱歉,我对音频处理更熟悉,但我喜欢玩OCR(光学字符识别)。所有这些都是为了说我需要你的帮助来重现你的原始结果。哦,你刚刚贴出了代码。我可能明天会更详细地看一下。希望你那时已经解决了问题,我可以从中学习到一些东西。 - bballdave025