我有一张发票图像,想要检测上面的文字。所以我计划采用两步来完成:首先是识别文本区域,然后使用OCR识别文本。
我正在使用Python中的OpenCV 3.0进行此操作。我能够识别文本(包括一些非文本区域),但我还想从图像中识别文本框(同时排除非文本区域)。
我的输入图像是:
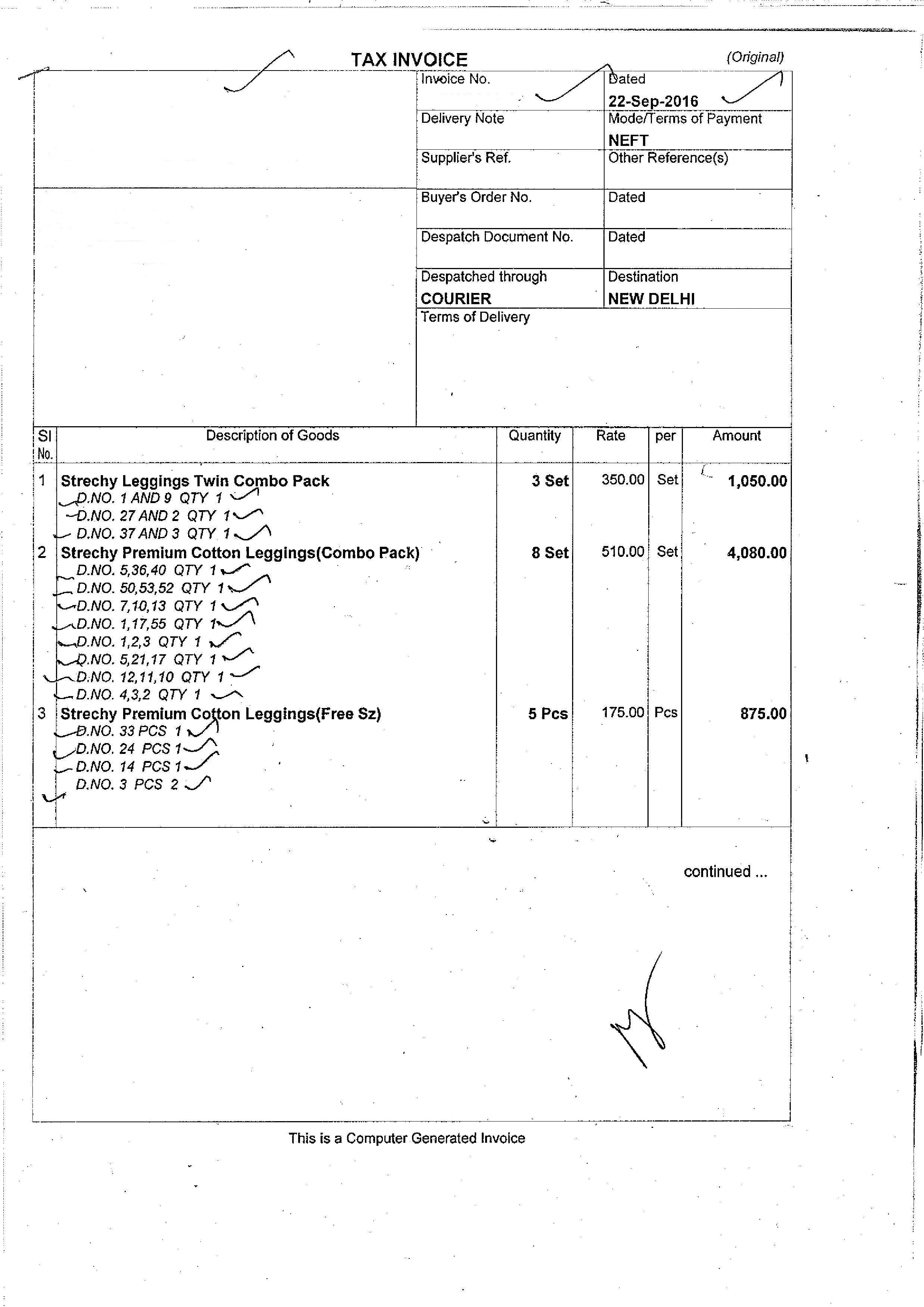
而输出结果如下:
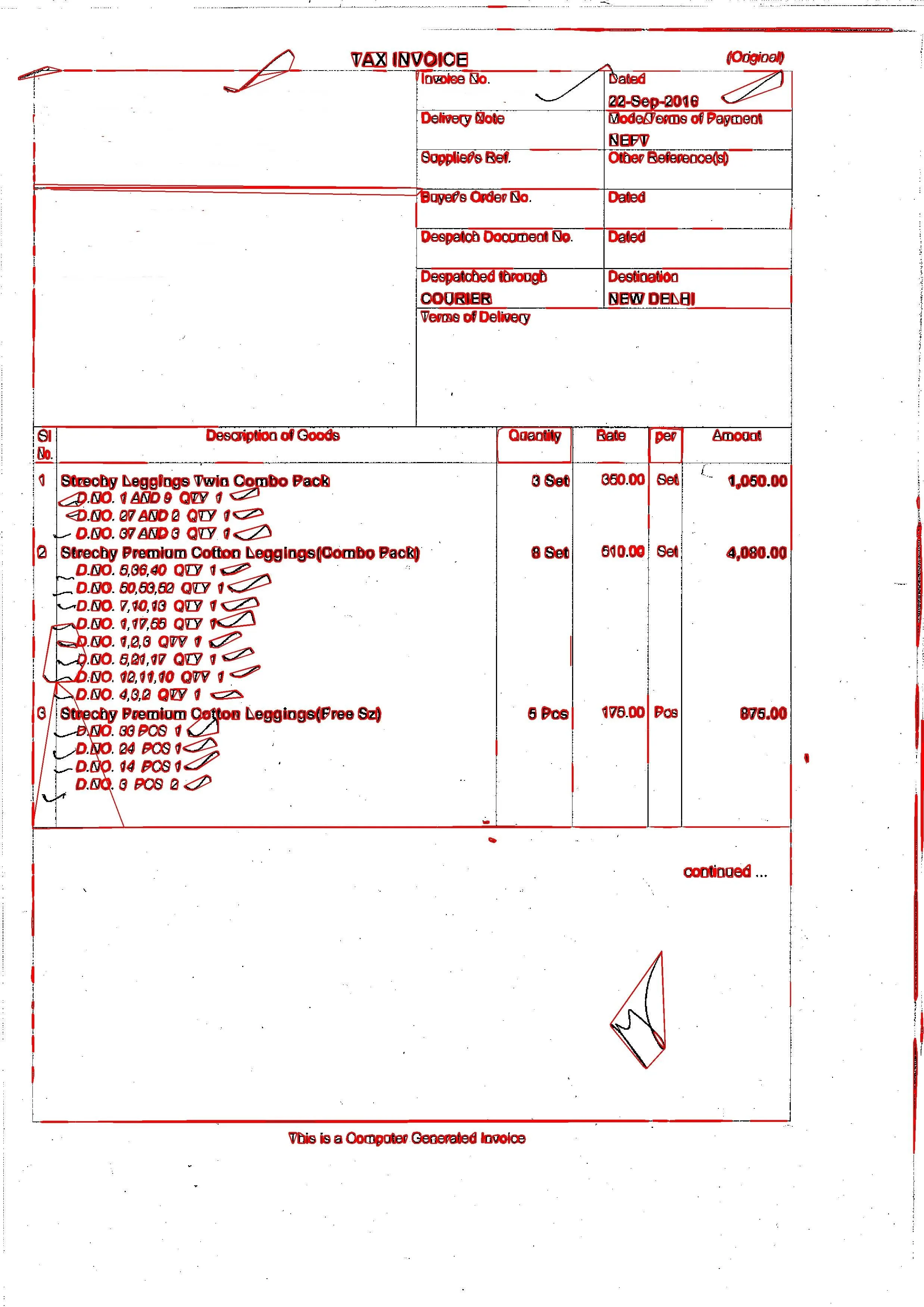
我使用了以下代码:
img = cv2.imread('/home/mis/Text_Recognition/bill.jpg')
mser = cv2.MSER_create()
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY) #Converting to GrayScale
gray_img = img.copy()
regions = mser.detectRegions(gray, None)
hulls = [cv2.convexHull(p.reshape(-1, 1, 2)) for p in regions]
cv2.polylines(gray_img, hulls, 1, (0, 0, 255), 2)
cv2.imwrite('/home/mis/Text_Recognition/amit.jpg', gray_img) #Saving