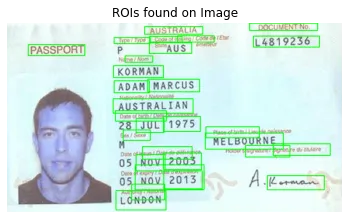
我正在使用OpenCV从各种护照图像中检测文本。任务是获取护照上的裁剪文本,例如姓名、出生日期、国籍等。当前代码如下:
image = cv2.imread(image) # read image
image = imutils.resize(image, height=600)
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
gray = cv2.GaussianBlur(gray, (3, 3), 0)
rectKernel = cv2.getStructuringElement(cv2.MORPH_RECT, (13, 5))
sqKernel = cv2.getStructuringElement(cv2.MORPH_RECT, (21, 21))
blackhat = cv2.morphologyEx(gray, cv2.MORPH_BLACKHAT, rectKernel)
gradX = cv2.Sobel(blackhat, ddepth=cv2.CV_32F, dx=1, dy=0, ksize=-1)
gradX = np.absolute(gradX)
(minVal, maxVal) = (np.min(gradX), np.max(gradX))
gradX = (255 * ((gradX - minVal) / (maxVal - minVal))).astype("uint8")
gradX = cv2.morphologyEx(gradX, cv2.MORPH_CLOSE, rectKernel)
thresh = cv2.threshold(gradX, 0, 255, cv2.THRESH_BINARY | cv2.THRESH_OTSU)[1]
if do_erosion: # do erosion if flag is True only
thresh = cv2.morphologyEx(thresh, cv2.MORPH_CLOSE, sqKernel)
thresh = cv2.erode(thresh, None, iterations=4)
p = int(image.shape[1] * 0.05)
thresh[:, 0:p] = 0
thresh[:, image.shape[1] - p:] = 0 # thresholded image shown below
cnts = cv2.findContours(thresh.copy(), cv2.RETR_EXTERNAL,
cv2.CHAIN_APPROX_SIMPLE) # finding contours from threshold image
cnts = imutils.grab_contours(cnts)
cnts = sorted(cnts, key=cv2.contourArea, reverse=True)
rois=[]
# loop over the contours
for c in cnts:
# compute the bounding box of the contour and use the contour to
# compute the aspect ratio and coverage ratio of the bounding box
# width to the width of the image
(x, y, w, h) = cv2.boundingRect(c)
ar = w / float(h)
crWidth = w / float(gray.shape[1])
# check to see if the aspect ratio and coverage width are within
# acceptable criteria
if ar > 2 and crWidth > 0.05:
# pad the bounding box since we applied erosions and now need
# to re-grow it
pX = int((x + w) * 0.03)
pY = int((y + h) * 0.03)
(x, y) = (x - pX, y - pY)
(w, h) = (w + (pX * 2), h + (pY * 2))
# extract the ROI from the image and draw a bounding box
# surrounding the MRZ
roi = original[y:y + h, x:x + w].copy() # interested in finding all ROIs having text
rois.append(roi)
cv2.rectangle(image, (x, y), (x + w, y + h), (0, 255, 0), 2)
我能正确检测到一些文本值,但解决方案并不通用。有时它只提取出生日期的年份,而不是完整的日期(有时它也会检测到月份和日期,但不在同一个ROI中)。下面显示了原始图像和阈值图像: