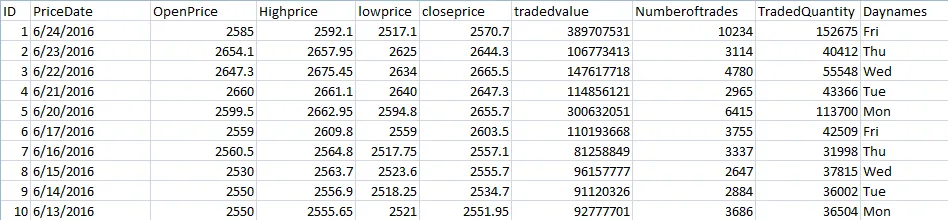
我正在使用Pandas通过数据框存储股票价格数据。该数据集中有2940行数据,如下所示:
import pandas as pd
import numpy as np
import os
os.chdir('C:/Users/Admin/Analytics/stock-prices')
data = pd.read_csv('stock-data.csv')
# PriceDate Column - Does not contain Saturday and Sunday stock entries
data['PriceDate'] = pd.to_datetime(data['PriceDate'], format='%m/%d/%Y')
data = data.sort_index(by=['PriceDate'], ascending=[True])
# Starting date is Aug 25 2004
idx = pd.date_range('08-25-2004',periods=2940,freq='D')
data = data.set_index(idx)
data['newdate']=data.index
newdate=data['newdate'].values # Create a time series column
data = pd.merge(newdate, data, on='PriceDate', how='outer')
如何填充周六和周日的缺失值?
data.set_index('PriceDate', inplace=True)。 - jezraeldata['new'] = data['PriceDate']吗? - jezraeldata = data.groupby('ID').resample('D').ffill().reset_index(level=0, drop=True).reset_index()- jezrael