我有一个pandas数据框,它有两列:locationid和geo_loc。locationid列中有缺失值。
我想获取缺失locationid行的geo_loc值, 然后在geo_loc列中搜索此geo_loc值并获取loction id。
我想获取缺失locationid行的geo_loc值, 然后在geo_loc列中搜索此geo_loc值并获取loction id。
df1 = pd.DataFrame({'locationid':[111, np.nan, 145, np.nan, 189,np.nan, 158, 145],
'geo_loc':['G12','K11','B16','G12','B22','B16', 'K11',he l 'B16']})
df
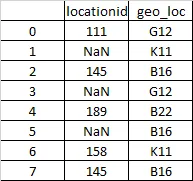
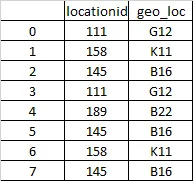
locationid的第1个索引缺失,相应的geo_loc值为'K11'。我会在geo_loc列中查找这个值,并且索引6具有locationid 158。使用此值,我想填充索引1的缺失值。
我尝试了这些代码,但它们没有起作用。
df1['locationid'] = df1.locationid.fillna(df1.groupby('geo_loc')['locationid'].max())
df1['locationid'] = df1.locationid.fillna(df1.groupby('geo_loc').apply(lambda x: print(list(x.locationid)[0])))
TypeError: '>='不支持'str'和'float'实例之间的比较。 - jezrael