我很好奇,所以我尝试用C++编写了这个东西,以下是一些见解:
structures
struct _pnt
{
int i0,i1,i2;
double pos[3];
_pnt() {}
_pnt(_pnt& a) { *this=a; }
~_pnt() {}
_pnt* operator = (const _pnt *a) { *this=*a; return this; }
};
struct _fac
{
int i0,i1,i2;
double nor[3];
double mid[3],d;
_fac() {}
_fac(_fac& a) { *this=a; }
~_fac() {}
_fac* operator = (const _fac *a) { *this=*a; return this; }
};
So I added indexes i0,i1,i2 of 3 adjacent non parallel triangles to each point. I also added mid point of each triangle and d normal offset to speed up computations but both can be computed when needed so you do not really need them to add to the mesh itself.
pre-computation
so you need to pre-compute nor,d,mid for each face that takes O(n) assuming n triangles and m points. And the adjacency indexes for each point are computed in O(m) so the whole thing is O(n+m) The adjacency is computed easily first clear i0,i1,i2 of all points. Then loop through all faces and for each add its index to each of its points if there are less than 3 normals and no normal is parallel to it.
offset
the offset is now done just by offsetting mid point by normal*offset_step recomputing d for all faces. After that you loop through all points and compute intersection of 3 planes you got index to. So this is also O(n+m).
I was too lazy to derive intersection equation so I used 3x3 inverse matrix instead. As my matrices are 4x4 the last row and column is unused. Beware my matrices are OpenGL like so they are transposed... that is why the normals are loaded so weirdly into it.
这是我的 C++ 源代码:
struct _pnt
{
int i0,i1,i2;
double pos[3];
_pnt() {}
_pnt(_pnt& a) { *this=a; }
~_pnt() {}
_pnt* operator = (const _pnt *a) { *this=*a; return this; }
};
struct _fac
{
int i0,i1,i2;
double nor[3];
double mid[3],d;
_fac() {}
_fac(_fac& a) { *this=a; }
~_fac() {}
_fac* operator = (const _fac *a) { *this=*a; return this; }
};
class mesh
{
public:
List<_pnt> pnt;
List<_fac> fac;
mesh() {}
mesh(mesh& a) { *this=a; }
~mesh() {}
mesh* operator = (const mesh *a) { *this=*a; return this; }
void icosahedron(double r)
{
double a=r*0.525731112119133606;
double b=r*0.850650808352039932;
_pnt p; p.i0=-1; p.i1=-1; p.i2=-1; pnt.num=0;
vector_ld(p.pos,-a,0.0, b); pnt.add(p);
vector_ld(p.pos, a,0.0, b); pnt.add(p);
vector_ld(p.pos,-a,0.0,-b); pnt.add(p);
vector_ld(p.pos, a,0.0,-b); pnt.add(p);
vector_ld(p.pos,0.0, b, a); pnt.add(p);
vector_ld(p.pos,0.0, b,-a); pnt.add(p);
vector_ld(p.pos,0.0,-b, a); pnt.add(p);
vector_ld(p.pos,0.0,-b,-a); pnt.add(p);
vector_ld(p.pos, b, a,0.0); pnt.add(p);
vector_ld(p.pos,-b, a,0.0); pnt.add(p);
vector_ld(p.pos, b,-a,0.0); pnt.add(p);
vector_ld(p.pos,-b,-a,0.0); pnt.add(p);
_fac f; fac.num=0; vector_ld(f.nor,0.0,0.0,0.0);
f.i0= 0; f.i1= 4; f.i2= 1; fac.add(f);
f.i0= 0; f.i1= 9; f.i2= 4; fac.add(f);
f.i0= 9; f.i1= 5; f.i2= 4; fac.add(f);
f.i0= 4; f.i1= 5; f.i2= 8; fac.add(f);
f.i0= 4; f.i1= 8; f.i2= 1; fac.add(f);
f.i0= 8; f.i1=10; f.i2= 1; fac.add(f);
f.i0= 8; f.i1= 3; f.i2=10; fac.add(f);
f.i0= 5; f.i1= 3; f.i2= 8; fac.add(f);
f.i0= 5; f.i1= 2; f.i2= 3; fac.add(f);
f.i0= 2; f.i1= 7; f.i2= 3; fac.add(f);
f.i0= 7; f.i1=10; f.i2= 3; fac.add(f);
f.i0= 7; f.i1= 6; f.i2=10; fac.add(f);
f.i0= 7; f.i1=11; f.i2= 6; fac.add(f);
f.i0=11; f.i1= 0; f.i2= 6; fac.add(f);
f.i0= 0; f.i1= 1; f.i2= 6; fac.add(f);
f.i0= 6; f.i1= 1; f.i2=10; fac.add(f);
f.i0= 9; f.i1= 0; f.i2=11; fac.add(f);
f.i0= 9; f.i1=11; f.i2= 2; fac.add(f);
f.i0= 9; f.i1= 2; f.i2= 5; fac.add(f);
f.i0= 7; f.i1= 2; f.i2=11; fac.add(f);
compute();
}
void compute()
{
int i,j,k;
_fac *f,*ff;
_pnt *p;
double a[3],b[3];
const double nor_dot=0.001;
for (f=fac.dat,i=0;i<fac.num;i++,f++)
{
vector_sub(a,pnt.dat[f->i1].pos,pnt.dat[f->i0].pos);
vector_sub(b,pnt.dat[f->i2].pos,pnt.dat[f->i0].pos);
vector_mul(a,b,a);
vector_one(f->nor,a);
}
for (f=fac.dat,i=0;i<fac.num;i++,f++)
{
vector_copy(a, pnt.dat[f->i0].pos);
vector_add (a,a,pnt.dat[f->i1].pos);
vector_add (a,a,pnt.dat[f->i2].pos);
vector_mul (f->mid,a,0.33333333333);
f->d=vector_mul(f->mid,f->nor);
}
for (p=pnt.dat,i=0;i<pnt.num;i++,p++)
{
p->i0=-1;
p->i1=-1;
p->i2=-1;
}
for (f=fac.dat,i=0;i<fac.num;i++,f++)
{
for (p=pnt.dat+f->i0;p->i2<0;)
{
if (p->i0>=0) { ff=fac.dat+p->i0; if (fabs(vector_mul(f->nor,ff->nor))<=nor_dot) break; } else { p->i0=i; break; }
if (p->i1>=0) { ff=fac.dat+p->i1; if (fabs(vector_mul(f->nor,ff->nor))<=nor_dot) break; } else { p->i1=i; break; }
p->i2=i; break;
}
for (p=pnt.dat+f->i1;p->i2<0;)
{
if (p->i0>=0) { ff=fac.dat+p->i0; if (fabs(vector_mul(f->nor,ff->nor))<=nor_dot) break; } else { p->i0=i; break; }
if (p->i1>=0) { ff=fac.dat+p->i1; if (fabs(vector_mul(f->nor,ff->nor))<=nor_dot) break; } else { p->i1=i; break; }
p->i2=i; break;
}
for (p=pnt.dat+f->i2;p->i2<0;)
{
if (p->i0>=0) { ff=fac.dat+p->i0; if (fabs(vector_mul(f->nor,ff->nor))<=nor_dot) break; } else { p->i0=i; break; }
if (p->i1>=0) { ff=fac.dat+p->i1; if (fabs(vector_mul(f->nor,ff->nor))<=nor_dot) break; } else { p->i1=i; break; }
p->i2=i; break;
}
}
}
void draw()
{
int i;
_fac *f;
glBegin(GL_TRIANGLES);
for (f=fac.dat,i=0;i<fac.num;i++,f++)
{
glNormal3dv(f->nor);
glVertex3dv(pnt.dat[f->i0].pos);
glVertex3dv(pnt.dat[f->i1].pos);
glVertex3dv(pnt.dat[f->i2].pos);
}
glEnd();
}
void draw_normals(double r)
{
int i;
double a[3];
_fac *f;
for (f=fac.dat,i=0;i<fac.num;i++,f++)
{
vector_mul (a,r,f->nor);
vector_add (a,a,f->mid);
glBegin(GL_LINES);
glVertex3dv(f->mid);
glVertex3dv(a);
glEnd();
glBegin(GL_LINE_LOOP);
glVertex3dv(pnt.dat[f->i0].pos);
glVertex3dv(pnt.dat[f->i1].pos);
glVertex3dv(pnt.dat[f->i2].pos);
glEnd();
}
}
void offset(double d)
{
int i,j;
_fac *f;
_pnt *p;
double a[3],m[16];
for (f=fac.dat,i=0;i<fac.num;i++,f++)
{
vector_mul(a,d,f->nor);
vector_add(f->mid,f->mid,a);
f->d=vector_mul(f->mid,f->nor);
}
for (p=pnt.dat,i=0;i<pnt.num;i++,p++)
if (p->i2>=0)
{
matrix_one(m);
for (f=fac.dat+p->i0,j=0;j<3;j++) m[0+(j<<2)]=f->nor[j]; a[0]=f->d;
for (f=fac.dat+p->i1,j=0;j<3;j++) m[1+(j<<2)]=f->nor[j]; a[1]=f->d;
for (f=fac.dat+p->i2,j=0;j<3;j++) m[2+(j<<2)]=f->nor[j]; a[2]=f->d;
matrix_inv(m,m);
matrix_mul_vector(p->pos,m,a);
}
}
};
这里是预览(左侧为源,然后应用了几次偏移)
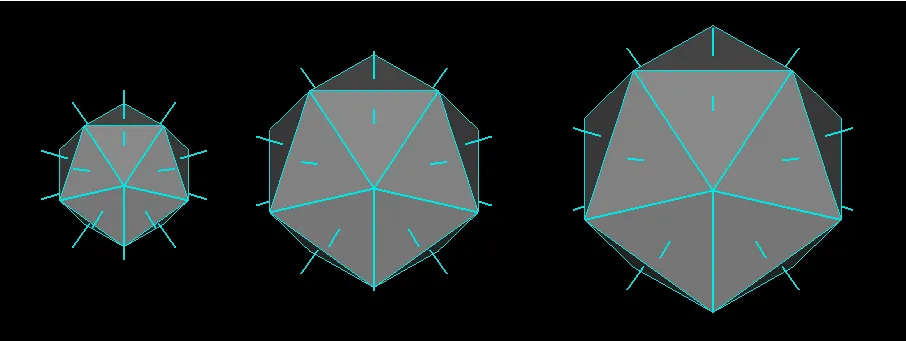
这也适用于负步长。使用方法如下:
mesh obj;
obj.icosahedron(0.5);
glFrontFace(GL_CW);
glEnable(GL_CULL_FACE);
glEnable(GL_LIGHTING);
glEnable(GL_LIGHT0);
glEnable(GL_COLOR_MATERIAL);
glColor3f(0.5,0.5,0.5);
obj.draw();
glDisable(GL_LIGHTING);
glColor3f(0.0,0.9,0.9);
glLineWidth(2.0);
obj.draw_normals(0.2);
glLineWidth(1.0);
if (WheelDelta>0) obj.offset(+0.05);
if (WheelDelta<0) obj.offset(-0.05);
我还使用我的动态列表模板,如下所示:
List<double> xxx; 相当于
double xxx[];
xxx.add(5); 在列表的末尾添加
5
xxx[7] 访问数组元素(安全)
xxx.dat[7] 访问数组元素(不安全但直接访问速度快)
xxx.num 是数组的实际使用大小
xxx.reset() 清除数组并设置
xxx.num=0
xxx.allocate(100) 预分配空间以容纳
100 个项目
此外,向量和矩阵数学源代码可以在此处找到:
O(1)的速度访问所有相邻平面。构建这样的LUT将需要O(n)的时间,其中n是三角形的数量。此外,我的直觉告诉我,每个点只需存储3个非共面三角形(无需存储所有相邻三角形)就足够了... - SpektreO(n+m)的解决方案。 - Spektre