使用.fit_generator()或.fit()训练图像分类器,并将字典作为参数传递给class_weight=。
在TF1.x中我从未遇到过错误,但在2.1中开始训练时会得到以下输出:
WARNING:tensorflow:sample_weight modes were coerced from
...
to
['...']
... 转换为 ['...'] 是什么意思?这是在
tensorflow 存储库上发出的警告,其源代码可以在此处找到:here。相关的评论如下:
Attempt to coerce sample_weight_modes to the target structure. This implicitly depends on the fact that Model flattens outputs for its internal representation.
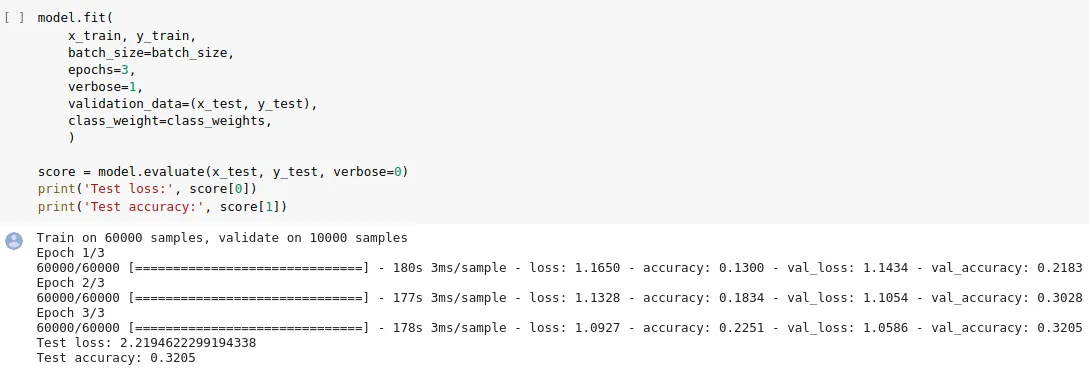
%tensorflow_version 2.x切换到TF2即可出现此警告:https://colab.research.google.com/gist/jorijnsmit/9a8fe5020f1c4d6e0c3a4a60329d3083/untitled2.ipynb - gosuto2.1.0rc0中引入的。 - gosuto