如果您有一个大的csv文件,我建议在I/O部分使用
pandas。
networkx有一个与
pandas交互的有用方法,称为
from_pandas_dataframe。 假设您的数据以上述格式存储在csv中,则此命令应该适用于您:
df = pd.read_csv('path/to/file.csv', columns=['node1', 'node2', 'weight'])
但为了演示,我将使用符合您要求的10个随机边缘(您不需要导入numpy,我只是用它来生成随机数):
import matplotlib as plt
import networkx as nx
import pandas as pd
import numpy as np
np.random.seed(0)
w = np.random.rand(10)
node1 = np.random.randint(10,19, (10))
node2 = np.random.randint(10,19, (10))
df = pd.DataFrame({'node1': node1, 'node2': node2, 'weight': w}, index=range(10))
前面的所有内容应该与您的
pd.read_csv命令生成相同。 这将导致此DataFrame,
df:
node1 node2 weight
0 16 13 0.548814
1 17 15 0.715189
2 17 10 0.602763
3 18 12 0.544883
4 11 13 0.423655
5 15 18 0.645894
6 18 11 0.437587
7 14 13 0.891773
8 13 13 0.963663
9 10 13 0.383442
使用
from_pandas_dataframe初始化
MultiGraph。这假设您将有多个边连接到一个节点(未在OP中指定)。要使用此方法,您将需要在
convert_matrix.py文件中对
networkx源代码进行简单更改,实现
这里(它是一个简单的错误)。
MG = nx.from_pandas_dataframe(df,
'node1',
'node2',
edge_attr='weight',
create_using=nx.MultiGraph()
)
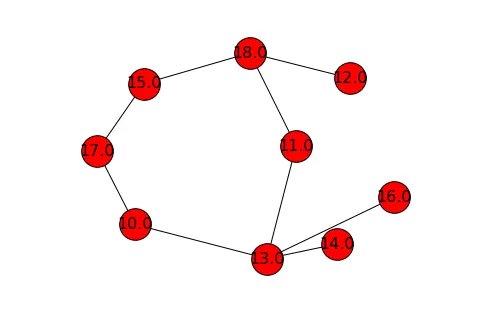
这将生成您的MultiGraph,您可以使用draw来可视化它:
positions = nx.spring_layout(MG)
nx.draw(MG, pos=positions, hold=True, with_labels=True, node_size=1000, font_size=16)
详细说明:
positions 是一个字典,其中每个节点都是一个键,其值是图表上的位置。我将在下面说明为什么我们存储
positions。通用的
draw 将使用指定的
positions 在你的 MultiGraph 实例
MG 上绘制节点。然而,正如你所看到的,边缘的宽度都是相同的:
但是你已经拥有了添加权重所需的一切。首先将权重放入名为 weights 的列表中。通过迭代(使用列表理解)每个边缘 edges,我们可以提取权重。我选择乘以5,因为它看起来最干净:
weights = [w[2]['weight']*5 for w in MG.edges(data=True)]
最后,我们将使用
draw_networkx_edges,它仅绘制图的边缘(没有节点)。由于我们有节点的
positions,并且我们设置了
hold=True,我们可以在前面的可视化上直接绘制加权边缘。
nx.draw_networkx_edges(MG, pos=positions, width=weights) #width can be array of floats
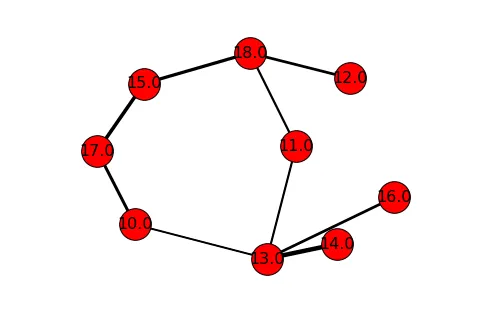
您可以看到节点
(14, 13) 在 DataFrame
df中具有最重的线和最大的值(除了
(13,13))。
{kind=link}
Graph而不是MultiGraph,则完全删除create_using参数也可以正常工作。 - Kevin