我目前正在尝试将fft应用于avr32微控制器进行信号处理,使用的是kiss fft。但在输出方面遇到了奇怪的问题。基本上,我将ADC样本(用函数发生器测试)传递给fft(实际输入,256n大小),并且检索到的输出对我来说是有意义的。
然而,如果我将汉明窗应用于ADC样本,然后将其传递给FFT,峰值幅度的频率处于错误位置(与未应用窗口的先前结果不同)。
ADC样本具有DC偏移,因此我消除了该偏移量,但仍无法使用带窗口的样本。
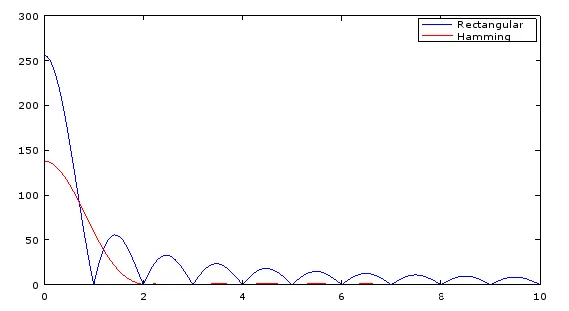
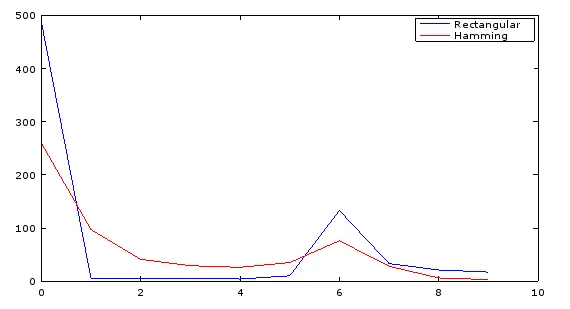
以下是通过rs485输出的前几个输出值。第一列是未使用窗口的fft输出,而第二列是使用窗口的输出。从第1列开始,峰值位于第6行(6 x fs(10.5kHz)/0.5N),为我提供了正确的输入频率结果,而第2列在第2行具有峰值幅度(除DC bin外),这对我来说没有意义。
任何建议都将有所帮助。
提前致谢。
kiss_fft_scalar zero;
memset(&zero,0,sizeof(zero));
kiss_fft_cpx fft_input[n];
kiss_fft_cpx fft_output[n];
for(ctr=0; ctr<n; ctr++)
{
fft_input[ctr].r = zero;
fft_input[ctr].i = zero;
fft_output[ctr].r =zero;
fft_output[ctr].i = zero;
}
// IIR filter calculation
for (ctr=0; ctr<n; ctr++)
{
// filter calculation
y[ctr] = num_coef[0]*x[ctr];
y[ctr] += (num_coef[1]*x[ctr-1]) - (den_coef[1]*y[ctr-1]);
y[ctr] += (num_coef[2]*x[ctr-2]) - (den_coef[2]*y[ctr-2]);
//y1[ctr] += y[ctr] - 500;
// hamming window
hamming[ctr] = (0.54-((0.46) * cos(2*PI*ctr/256)));
window[ctr] = hamming[ctr]*y[ctr];
fft_input[ctr].r = window[ctr];
fft_input[ctr].i = 0;
fft_output[ctr].r = 0;
fft_output[ctr].i = 0;
}
kiss_fftr_cfg fftConfig = kiss_fftr_alloc(n,0,NULL,NULL);
kiss_fftr(fftConfig, (kiss_fft_scalar * )fft_input, fft_output);
for (ctr=0; ctr<n; ctr++)
{
fft_mag[ctr] = (sqrt((fft_output[ctr].r * fft_output[ctr].r) + (fft_output[ctr].i * fft_output[ctr].i)))/(0.5*n);
//Usart write
char filtResult[10];
sprintf(filtResult, "%04d %04d\n", (int)x[ctr], (int)fft_mag[ctr]);
//sprintf(filtResult, "%04d %04d\n", (int)x[ctr], (int)window[ctr]);
char c;
char *ptr = &filtResult[0];
do
{
c = *ptr;
ptr++;
usart_bw_write_char(&AVR32_USART2, (int)c);
// sendByte(c);
} while (c != '\n');
}
kiss_fft_cleanup();
free(fftConfig);