我有一个数据框,如下所示已经聚合。但是,我希望将它们做差,即最大值减去最小值。
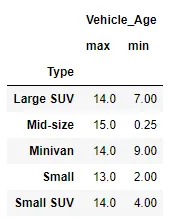
dnm=df.groupby('Type').agg({'Vehicle_Age': ['max','min']})
期望:
期望的结果是一个文本框,用户能够在其中输入文本并提交该文本。用户提交的文本会被传递给后端处理。
np.ptp,它会为你计算max - min:df.groupby('Type').agg({'Vehicle_Age': np.ptp})
或者,
df.groupby('Type')['Vehicle_Age'].agg(np.ptp)
只需比较这两个:
grouping = df.groupby('Type')
dnm = grouping.max() - grouping.min()
df = pd.DataFrame({'a':np.arange(100),'Type':[1 if i %2 ==0 else 0 for i in range(100)]})
%timeit df.groupby('Type').agg({'a': np.ptp})
1.29 ms ± 39.5 µs per loop (mean ± std. dev. of 7 runs, 1000 loops each)
vs
%%timeit
grouping = df.groupby('Type')
dnm = grouping.max() - grouping.min()
1.57 ms ± 299 µs per loop (mean ± std. dev. of 7 runs, 1000 loops each)
import pandas as pd
# This is just setup to replicate your example
df = pd.DataFrame([[14, 7], [15, .25], [14, 9], [13, 2], [14, 4]], index=['Large SUV', 'Mid-size', 'Minivan', 'Small', 'Small SUV'], columns = ['max', 'min'])
print(df)
# max min
# Large SUV 14 7.00
# Mid-size 15 0.25
# Minivan 14 9.00
# Small 13 2.00
# Small SUV 14 4.00
# This is the operation that will give you the values you want
diff = df['max'] - df['min']
print(diff)
# Large SUV 7.00
# Mid-size 14.75
# Minivan 5.00
# Small 11.00
# Small SUV 10.00
%timeit df.groupby('Type').agg({'a': np.ptp}) 1.29毫秒±39.5微秒每个循环(7次运行的平均值±标准差,每个循环1000次)与%%timeit grouping = df.groupby('Type') dnm = grouping.max() - grouping.min() 1.57毫秒±299微秒每个循环(7次运行的平均值±标准差,每个循环1000次)。 - adir abargil