给定一个长这样的数据框
GROUP VALUE
1 5
2 2
1 10
2 20
1 7
我希望计算每个组中最大值和最小值之间的差异。也就是说,结果应该是:
GROUP DIFF
1 5
2 18
在Pandas中,有什么简单的方法可以做到这一点?
对于一个拥有大约200万行和100万组的数据框,在Pandas中有什么快速的方法可以做到这一点?
使用 @unutbu 的 df
按时间计算
在大数据集上,unutbu的解决方案是最好的。
import pandas as pd
import numpy as np
df = pd.DataFrame({'GROUP': [1, 2, 1, 2, 1], 'VALUE': [5, 2, 10, 20, 7]})
df.groupby('GROUP')['VALUE'].agg(np.ptp)
GROUP
1 5
2 18
Name: VALUE, dtype: int64
np.ptp 文档 返回数组的范围。
时间
小型 df
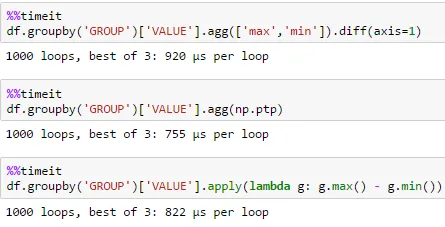
大型 df
df = pd.DataFrame(dict(GROUP=np.arange(1000000) % 100, VALUE=np.random.rand(1000000)))
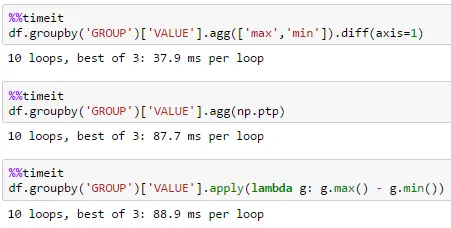
大型 df
许多组
df = pd.DataFrame(dict(GROUP=np.arange(1000000) % 10000, VALUE=np.random.rand(1000000)))
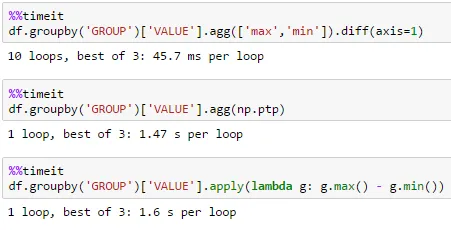
groupby/agg通常在利用内置聚合函数,如'max'和'min'时表现最佳。因此,要获得差异,请首先计算max和min,然后相减:
import pandas as pd
df = pd.DataFrame({'GROUP': [1, 2, 1, 2, 1], 'VALUE': [5, 2, 10, 20, 7]})
result = df.groupby('GROUP')['VALUE'].agg(['max','min'])
result['diff'] = result['max']-result['min']
print(result[['diff']])
diff
GROUP
1 5
2 18
agg(np.ptp) 在大量分组情况下表现更好! - piRSquareddf所有列(按GROUP)的min和max,那么只需删除['VALUE']即可。也就是说,使用df.groupby('GROUP').agg(['max', 'min'])。如果您希望找到某些但不是所有列的每个GROUP的min,max,请先限制df:df[['GROUP','VALUE1','VALUE2']] .groupby('GROUP').agg(['max','min'])。 - unutbudf.groupby('GROUP').agg(['last','first']).stack(level=0).diff(axis=1).unstack(-1)['last']。但我觉得这样写不是很易读。也许用3行更好:result = df.groupby('GROUP').agg(['last','first']),result = result.reorder_levels([1,0], axis=1),result['last'] - result['first']。 - unutbu注意:这样做可以完成工作,但@piRSquared的答案有更快的方法。
您可以使用groupby(),min()和max():
df.groupby('GROUP')['VALUE'].apply(lambda g: g.max() - g.min())