在R中有预先构建的函数来绘制随机森林模型的特征重要性。但在Python中似乎缺少这种方法。我在matplotlib中搜索了一种方法。
model.feature_importances给我以下结果:
model.feature_importances给我以下结果:
array([ 2.32421835e-03, 7.21472336e-04, 2.70491223e-03,
3.34521084e-03, 4.19443238e-03, 1.50108737e-03,
3.29160540e-03, 4.82320256e-01, 3.14117333e-03])
然后使用以下绘图函数:
>> pyplot.bar(range(len(model.feature_importances_)), model.feature_importances_)
>> pyplot.show()
我得到了一个条形图,但是我想要一个带标签的条形图,并且水平显示按排序方式显示的重要性。我也在探索 seaborn ,但是没有找到相应的方法。
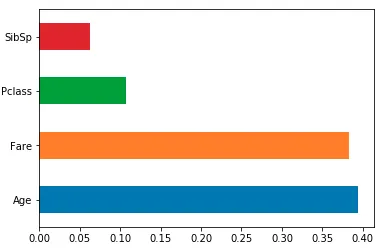
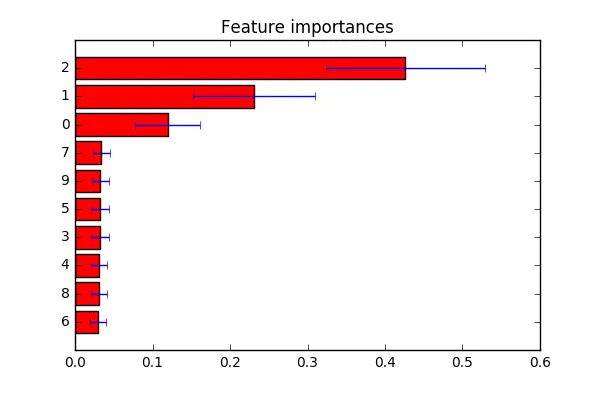
barh(水平条形图)。将特征名称作为tick_label传递。 - DYZ