我有一个函数,使用
numpy.interp和scipy.integrate.quad来进行某个积分。由于我使用quad进行积分,根据其文档:
我需要使用A Python function or method to integrate. If
functakes many arguments, it is integrated along the axis corresponding to the first argument.If the user desires improved integration performance, then
fmay be ascipy.LowLevelCallablewith one of the signatures:double func(double x) double func(double x, void *user_data) double func(int n, double *xx) double func(int n, double *xx, void *user_data)The user_data is the data contained in the
scipy.LowLevelCallable. In the call forms withxx,nis the length of thexxarray which containsxx[0] == xand the rest of the items are numbers contained in the args argument of quad.In addition, certain ctypes call signatures are supported for backward compatibility, but those should not be used in new code.
scipy.LowLevelCallable对象来加速我的代码,并且我需要将我的函数设计与上述签名之一保持一致。此外,由于我不想用C库和编译器使整个事情变得复杂,我想通过numba提供的工具“即时解决”,特别是numba.cfunc,它允许我绕过Python C API。
我已经能够解决这个积分问题,该积分问题以积分变量和任意数量的标量参数作为输入:
from scipy import integrate, LowLevelCallable
from numba import njit, cfunc
from numba.types import intc, float64, CPointer
def jit_integrand_function(integrand_function):
jitted_function = njit(integrand_function)
@cfunc(float64(intc, CPointer(float64)))
def wrapped(n, xx):
return jitted_function(xx[0], xx[1], xx[2], xx[3])
return LowLevelCallable(wrapped.ctypes)
@jit_integrand_function
def regular_function(x1, x2, x3, x4):
return x1 + x2 + x3 + x4
def do_integrate_wo_arrays(a, b, c, lolim=0, hilim=1):
return integrate.quad(regular_function, lolim, hilim, (a, b, c))
>>> print(do_integrate_wo_arrays(1,2,3,lolim=2, hilim=10))
(96.0, 1.0658141036401503e-12)
这段代码运行良好。我能够jit积分函数并将其作为
LowLevelCallable对象返回。然而,实际上我需要向我的积分函数传递两个numpy.array,而上述构造会导致错误: from scipy import integrate, LowLevelCallable
from numba import njit, cfunc
from numba.types import intc, float64, CPointer
def jit_integrand_function(integrand_function):
jitted_function = njit(integrand_function)
@cfunc(float64(intc, CPointer(float64)))
def wrapped(n, xx):
return jitted_function(xx[0], xx[1], xx[2], xx[3])
return LowLevelCallable(wrapped.ctypes)
@jit_integrand_function
def function_using_arrays(x1, x2, array1, array2):
res1 = np.interp(x1, array1[0], array1[1])
res2 = np.interp(x2, array2[0], array2[1])
return res1 + res2
def do_integrate_w_arrays(a, lolim=0, hilim=1):
foo = np.arange(20, dtype=np.float).reshape(2, -1)
bar = np.arange(60, dtype=np.float).reshape(2, -1)
return integrate.quad(function_using_arrays, lolim, hilim, (a, foo, bar))
>>> print(do_integrate_w_arrays(3, lolim=2, hilim=10))
Traceback (most recent call last):
File "C:\ProgramData\Miniconda3\lib\site-packages\IPython\core\interactiveshell.py", line 3267, in run_code
exec(code_obj, self.user_global_ns, self.user_ns)
File "<ipython-input-63-69c0074d4936>", line 1, in <module>
runfile('C:/Users/mosegui/Desktop/fos4x_pkg_develop/python-packages/fos4x_tec/fos4x_tec/test_scipy_numba.py', wdir='C:/Users/mosegui/Desktop/fos4x_pkg_develop/python-packages/fos4x_tec/fos4x_tec')
File "C:\Program Files\JetBrains\PyCharm Community Edition 2018.3.4\helpers\pydev\_pydev_bundle\pydev_umd.py", line 197, in runfile
pydev_imports.execfile(filename, global_vars, local_vars) # execute the script
File "C:\Program Files\JetBrains\PyCharm Community Edition 2018.3.4\helpers\pydev\_pydev_imps\_pydev_execfile.py", line 18, in execfile
exec(compile(contents+"\n", file, 'exec'), glob, loc)
File "C:/Users/mosegui/Desktop/fos4x_pkg_develop/python-packages/fos4x_tec/fos4x_tec/test_scipy_numba.py", line 29, in <module>
@jit_integrand_function
File "C:/Users/mosegui/Desktop/fos4x_pkg_develop/python-packages/fos4x_tec/fos4x_tec/test_scipy_numba.py", line 13, in jit_integrand_function
@cfunc(float64(intc, CPointer(float64)))
File "C:\Users\mosegui\AppData\Roaming\Python\Python36\site-packages\numba\decorators.py", line 260, in wrapper
res.compile()
File "C:\Users\mosegui\AppData\Roaming\Python\Python36\site-packages\numba\compiler_lock.py", line 32, in _acquire_compile_lock
return func(*args, **kwargs)
File "C:\Users\mosegui\AppData\Roaming\Python\Python36\site-packages\numba\ccallback.py", line 69, in compile
cres = self._compile_uncached()
File "C:\Users\mosegui\AppData\Roaming\Python\Python36\site-packages\numba\ccallback.py", line 82, in _compile_uncached
cres = self._compiler.compile(sig.args, sig.return_type)
File "C:\Users\mosegui\AppData\Roaming\Python\Python36\site-packages\numba\dispatcher.py", line 81, in compile
raise retval
File "C:\Users\mosegui\AppData\Roaming\Python\Python36\site-packages\numba\dispatcher.py", line 91, in _compile_cached
retval = self._compile_core(args, return_type)
File "C:\Users\mosegui\AppData\Roaming\Python\Python36\site-packages\numba\dispatcher.py", line 109, in _compile_core
pipeline_class=self.pipeline_class)
File "C:\Users\mosegui\AppData\Roaming\Python\Python36\site-packages\numba\compiler.py", line 528, in compile_extra
return pipeline.compile_extra(func)
File "C:\Users\mosegui\AppData\Roaming\Python\Python36\site-packages\numba\compiler.py", line 326, in compile_extra
return self._compile_bytecode()
File "C:\Users\mosegui\AppData\Roaming\Python\Python36\site-packages\numba\compiler.py", line 385, in _compile_bytecode
return self._compile_core()
File "C:\Users\mosegui\AppData\Roaming\Python\Python36\site-packages\numba\compiler.py", line 365, in _compile_core
raise e
File "C:\Users\mosegui\AppData\Roaming\Python\Python36\site-packages\numba\compiler.py", line 356, in _compile_core
pm.run(self.state)
File "C:\Users\mosegui\AppData\Roaming\Python\Python36\site-packages\numba\compiler_machinery.py", line 328, in run
raise patched_exception
File "C:\Users\mosegui\AppData\Roaming\Python\Python36\site-packages\numba\compiler_machinery.py", line 319, in run
self._runPass(idx, pass_inst, state)
File "C:\Users\mosegui\AppData\Roaming\Python\Python36\site-packages\numba\compiler_lock.py", line 32, in _acquire_compile_lock
return func(*args, **kwargs)
File "C:\Users\mosegui\AppData\Roaming\Python\Python36\site-packages\numba\compiler_machinery.py", line 281, in _runPass
mutated |= check(pss.run_pass, internal_state)
File "C:\Users\mosegui\AppData\Roaming\Python\Python36\site-packages\numba\compiler_machinery.py", line 268, in check
mangled = func(compiler_state)
File "C:\Users\mosegui\AppData\Roaming\Python\Python36\site-packages\numba\typed_passes.py", line 94, in run_pass
state.locals)
File "C:\Users\mosegui\AppData\Roaming\Python\Python36\site-packages\numba\typed_passes.py", line 66, in type_inference_stage
infer.propagate()
File "C:\Users\mosegui\AppData\Roaming\Python\Python36\site-packages\numba\typeinfer.py", line 951, in propagate
raise errors[0]
numba.errors.TypingError: Failed in nopython mode pipeline (step: nopython frontend)
Failed in nopython mode pipeline (step: nopython frontend)
Invalid use of Function(<built-in function getitem>) with argument(s) of type(s): (float64, Literal[int](0))
* parameterized
In definition 0:
All templates rejected with literals.
In definition 1:
All templates rejected without literals.
In definition 2:
All templates rejected with literals.
In definition 3:
All templates rejected without literals.
In definition 4:
All templates rejected with literals.
In definition 5:
All templates rejected without literals.
In definition 6:
All templates rejected with literals.
In definition 7:
All templates rejected without literals.
In definition 8:
All templates rejected with literals.
In definition 9:
All templates rejected without literals.
In definition 10:
All templates rejected with literals.
In definition 11:
All templates rejected without literals.
In definition 12:
All templates rejected with literals.
In definition 13:
All templates rejected without literals.
This error is usually caused by passing an argument of a type that is unsupported by the named function.
[1] During: typing of intrinsic-call at C:/Users/mosegui/Desktop/fos4x_pkg_develop/python-packages/fos4x_tec/fos4x_tec/test_scipy_numba.py (32)
[2] During: typing of static-get-item at C:/Users/mosegui/Desktop/fos4x_pkg_develop/python-packages/fos4x_tec/fos4x_tec/test_scipy_numba.py (32)
File "test_scipy_numba.py", line 32:
def diff_moment_edge(radius, alpha, chord_df, aerodyn_df):
<source elided>
# # calculate blade twist for radius
# sensor_twist = np.arctan((2 * rated_wind_speed) / (3 * rated_rotor_speed * (sensor_radius / 30.0) * radius)) * (180.0 / np.pi)
^
[1] During: resolving callee type: type(CPUDispatcher(<function function_using_arrays at 0x0000020C811827B8>))
[2] During: typing of call at C:/Users/mosegui/Desktop/fos4x_pkg_develop/python-packages/fos4x_tec/fos4x_tec/test_scipy_numba.py (15)
[3] During: resolving callee type: type(CPUDispatcher(<function function_using_arrays at 0x0000020C811827B8>))
[4] During: typing of call at C:/Users/mosegui/Desktop/fos4x_pkg_develop/python-packages/fos4x_tec/fos4x_tec/test_scipy_numba.py (15)
File "test_scipy_numba.py", line 15:
def jit_integrand_function(integrand_function):
<source elided>
jitted_function = njit(integrand_function)
^
显然,这个例子不起作用,因为我没有修改装饰器的设计。但这正是我的问题的核心:我不完全理解这种情况,因此不知道如何修改cfunc参数以传递数组作为参数,并仍符合scipy.integrate.quad签名要求。在介绍CPointers的numba文档中,有一个示例说明如何将数组传递给numba.cfunc:
我大致理解Native platform ABIs as used by C or C++ don’t have the notion of a shaped array as in Numpy. One common solution is to pass a raw data pointer and one or several size arguments (depending on dimensionality). Numba must provide a way to rebuild an array view of this data inside the callback.
from numba import cfunc, carray from numba.types import float64, CPointer, void, intp # A callback with the C signature `void(double *, double *, size_t)` @cfunc(void(CPointer(float64), CPointer(float64), intp)) def invert(in_ptr, out_ptr, n): in_ = carray(in_ptr, (n,)) out = carray(out_ptr, (n,)) for i in range(n): out[i] = 1 / in_[i] ```
CPointer 用于在 C 中构建数组,就像我的装饰器示例中的签名 CPointer(float64) 收集所有传递的浮点数并将它们放入数组中。但是,我仍然无法将其整合起来,看到如何使用它来传递数组,而不是将一系列传递的 float 参数制作成数组。
编辑:
@max9111 的答案有效,因为能够向 scipy.integrate.quad 传递一个 LowLevelCallable,从而提高了计算的时间效率。这非常有价值,因为现在更清楚地了解了 C 中内存地址管理的工作方式。即使结构化数组的概念在本机 C 中不存在,我仍然可以在 Python 中创建一个结构化数组,并将 C 要存储在连续内存区域中的数据存储在其中,并通过唯一的内存地址访问它/指向它。结构化数组提供的映射允许识别该内存区域的不同组件。尽管
@max9111的解决方案有效并解决了我最初发布的问题,但从Python的角度来看,这种方法引入了一定的开销,在某些条件下,这种开销可能比现在通过LowLevelCallable调用scipy.integrate.quad积分函数所节省的时间更耗时。在我的实际情况中,我将积分作为二维优化问题的一步。每个优化步骤需要两次积分,而积分需要九个标量参数和两个数组。只要我还没有能够通过
LowLevelCallable解决积分问题,我所能做的唯一事情就是简单地将积分函数njit。尽管积分仍然是通过Python API触发的,但这种方法效果还不错。在我的情况下,实施
@max9111的解决方案大大提高了积分时间的效率(从每个步骤约0.0009秒到约0.0005秒)。然而,创建结构化数组、C解压数据、将其传递给jitted积分函数并返回一个LowLevelCallable的步骤平均每次迭代额外增加了0.3秒,从而恶化了我的情况。
这里有一些玩具代码,展示了当一个迭代过程变得越来越复杂时,LowLevelCallable方法变得越来越不好用的情况:
import ctypes
import timeit
from tqdm import tqdm
import numpy as np
from scipy import integrate, LowLevelCallable
import numba as nb
from numba import types
import matplotlib.pyplot as plt
##################################################
# creating some sample data and parameters
a = 3
foo = np.arange(200, dtype=np.float64).reshape(2, -1)
bar = np.arange(600, dtype=np.float64).reshape(2, -1)
lim1 = 0
lim2 = 1
@nb.njit
def function_using_arrays(x1, x2, array1, array2):
res1 = np.interp(x1, array1[0], array1[1])
res2 = np.interp(x2, array2[0], array2[1])
return res1 + res2
##################################################
# JIT INTEGRAND
def do_integrate_w_arrays_jit(a, array1, array2, lolim=0, hilim=1):
return integrate.quad(function_using_arrays, lolim, hilim, (a, array1, array2))
def process_jit_integrand():
do_integrate_w_arrays_jit(a, foo, bar, lolim=lim1, hilim=lim2)
##################################################
# LOWLEV CALLABLE
def create_jit_integrand_function(integrand_function,args,args_dtype):
@nb.cfunc(types.float64(types.float64,types.CPointer(args_dtype)))
def wrapped(x1,user_data_p):
#Array of structs
user_data = nb.carray(user_data_p, 1)
#Extract the data
x2=user_data[0].a
array1=user_data[0].foo
array2=user_data[0].bar
return integrand_function(x1, x2, array1, array2)
return wrapped
def do_integrate_w_arrays_lowlev(func,args,lolim=0, hilim=1):
integrand_func = LowLevelCallable(func.ctypes,user_data=args.ctypes.data_as(ctypes.c_void_p))
return integrate.quad(integrand_func, lolim, hilim)
def process_lowlev_callable():
args_dtype = types.Record.make_c_struct([
('a', types.float64),
('foo', types.NestedArray(dtype=types.float64, shape=foo.shape)),
('bar', types.NestedArray(dtype=types.float64, shape=bar.shape)),])
args=np.array((a, foo, bar), dtype=args_dtype)
func = create_jit_integrand_function(function_using_arrays,args,args_dtype)
do_integrate_w_arrays_lowlev(func, args, lolim=0, hilim=1)
##################################################
repetitions = range(100)
jit_integrand_delays = [timeit.timeit(stmt=process_jit_integrand,
number=repetition) for repetition in tqdm(repetitions)]
lowlev_callable_delays = [timeit.timeit(stmt=process_lowlev_callable,
number=repetition) for repetition in tqdm(repetitions)]
fig, ax = plt.subplots()
ax.plot(repetitions, jit_integrand_delays, label="jit_integrand")
ax.plot(repetitions, lowlev_callable_delays, label="lowlev_callable")
ax.set_xlabel('number of repetitions')
ax.set_ylabel('calculation time (s)')
ax.set_title("Comparison calculation time")
plt.tight_layout()
plt.legend()
plt.savefig(f'calculation_time_comparison_{repetitions[-1]}_reps.png')
以下对比了两种选项(仅在积分被击中的情况下与@max9111的解决方案)。在@max9111解决方案的修改版本中,我已经永久地击中了积分函数(function_using_arrays)并从create_jit_integrand_function中删除了这一步骤,这将“开销”时间减少了20%。此外,为了加快速度,我还抑制了jit_with_dummy_data函数,并将其功能包含在process_lowlev_callable的主体中,基本上是为了避免不必要的函数调用。请在以下找到两种解决方案在多达100个周期的计算时间:
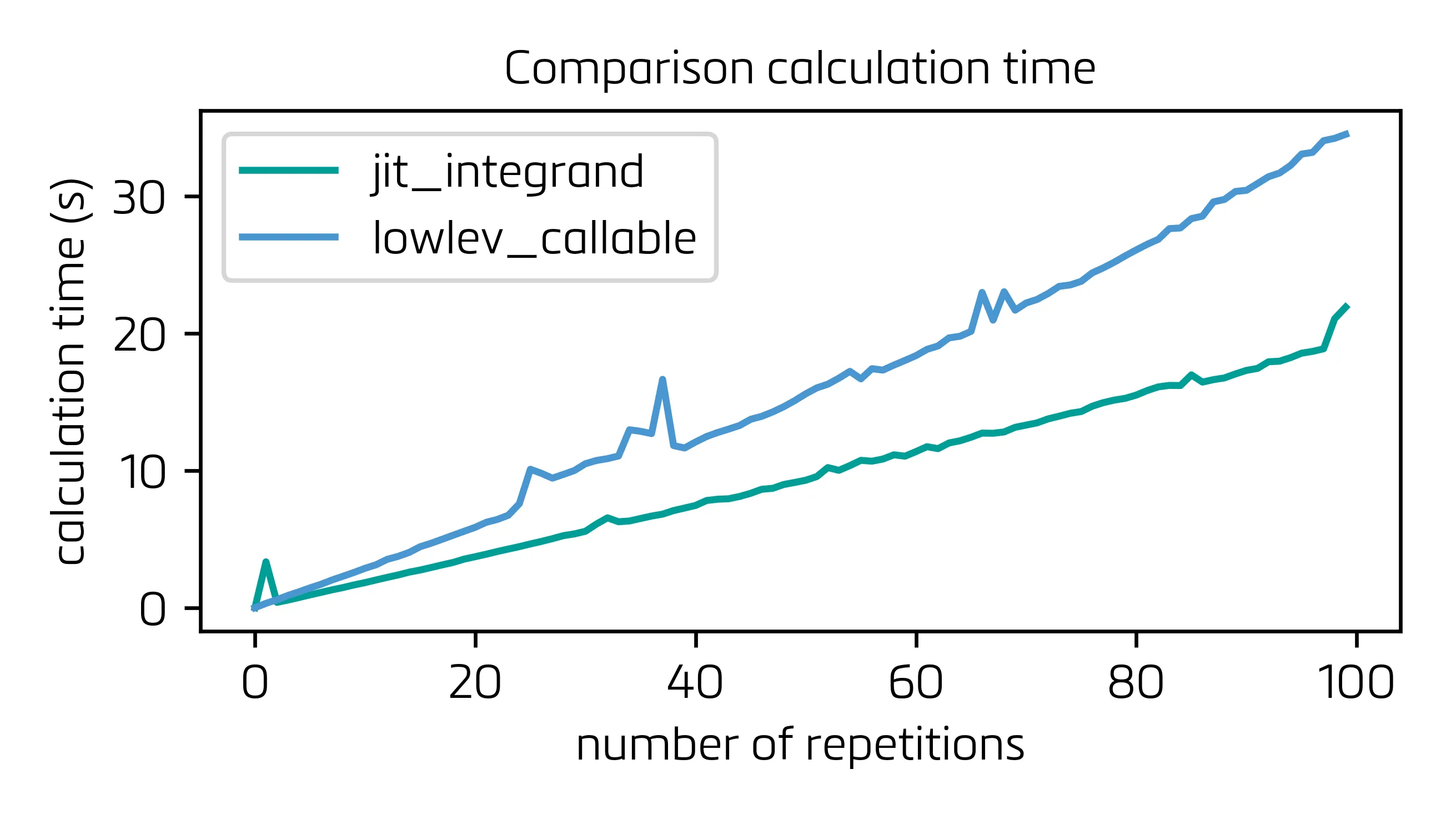
底线:对于减少单个非常重要的积分计算时间,此解决方案非常好,但是当解决迭代过程中的平均积分时,似乎仅jit积分更好,因为LowlevelCallable需要的额外函数,需要与积分本身一样频繁地调用,因此会产生负担。
无论如何,非常感谢。尽管这个解决方案对我不起作用,但我学到了有价值的东西,并且我认为我的问题已经解决了。
编辑2:
我误解了@max9111解决方案的某些部分以及create_jit_integrand_function函数所扮演的角色,并且错误地在优化的每个步骤中编译LowLevelCallable(因为即使传递给积分的参数和数组每次迭代都会改变,它们的形状,因此C结构的形状保持不变)。
上面编辑的重构代码版本已经更加合理:
import ctypes
import timeit
from tqdm import tqdm
import numpy as np
from scipy import integrate, LowLevelCallable
import numba as nb
from numba import types
import matplotlib.pyplot as plt
##################################################
# creating some sample data and parameters
a = 3
foo = np.arange(200, dtype=np.float64).reshape(2, -1)
bar = np.arange(600, dtype=np.float64).reshape(2, -1)
lim1 = 0
lim2 = 1
def function_using_arrays(x1, x2, array1, array2):
res1 = np.interp(x1, array1[0], array1[1])
res2 = np.interp(x2, array2[0], array2[1])
return res1 + res2
##################################################
# JIT INTEGRAND
def do_integrate_w_arrays_jit(a, array1, array2, lolim=0, hilim=1):
return integrate.quad(nb.njit(function_using_arrays), lolim, hilim, (a, array1, array2))
def process_jit_integrand():
do_integrate_w_arrays_jit(a, foo, bar, lolim=lim1, hilim=lim2)
##################################################
# LOWLEV CALLABLE
def create_jit_integrand_function(integrand_function, args_dtype):
jitted_function = nb.njit(integrand_function)
@nb.cfunc(types.float64(types.float64,types.CPointer(args_dtype)))
def wrapped(x1,user_data_p):
#Array of structs
user_data = nb.carray(user_data_p, 1)
#Extract the data
x2=user_data[0].a
array1=user_data[0].foo
array2=user_data[0].bar
return jitted_function(x1, x2, array1, array2)
return wrapped
def do_integrate_w_arrays_lowlev(func,args,lolim=0, hilim=1):
integrand_func=LowLevelCallable(func.ctypes,user_data=args.ctypes.data_as(ctypes.c_void_p))
return integrate.quad(integrand_func, lolim, hilim)
def process_lowlev_callable():
do_integrate_w_arrays_lowlev(func, np.array((a, foo, bar), dtype=args_dtype), lolim=0, hilim=1)
##################################################
repetitions = range(100)
jit_integrand_delays = [timeit.timeit(stmt=process_jit_integrand, number=repetition) for repetition in tqdm(repetitions)]
args_dtype = types.Record.make_c_struct([
('a', types.float64),
('foo', types.NestedArray(dtype=types.float64, shape=foo.shape)),
('bar', types.NestedArray(dtype=types.float64, shape=bar.shape)),])
func = create_jit_integrand_function(function_using_arrays, args_dtype)
lowlev_callable_delays = [timeit.timeit(stmt=process_lowlev_callable, number=repetition) for repetition in tqdm(repetitions)]
fig, ax = plt.subplots()
ax.plot(repetitions, jit_integrand_delays, label="jit_integrand")
ax.plot(repetitions, lowlev_callable_delays, label="lowlev_callable")
ax.set_xlabel('number of repetitions')
ax.set_ylabel('calculation time (s)')
ax.set_title("Comparison calculation time")
plt.tight_layout()
plt.legend()
plt.savefig(f'calculation_time_comparison_{repetitions[-1]}_reps.png')
在这种配置中,
LowLevelCallable的构建(确实需要一些时间)只需要进行一次,整个过程的速度快了几个数量级:
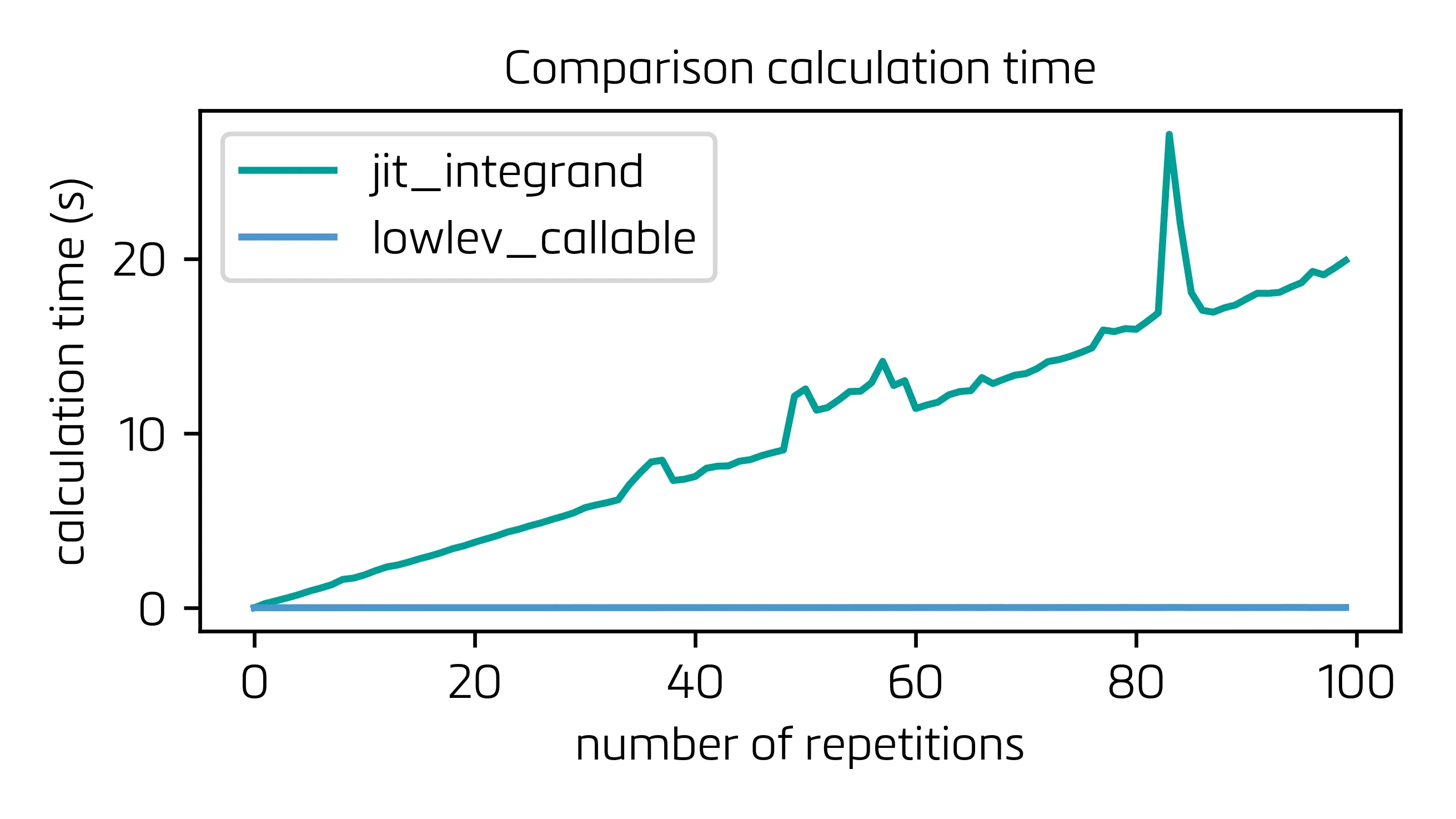
并且对于lowlev_callable的特写:
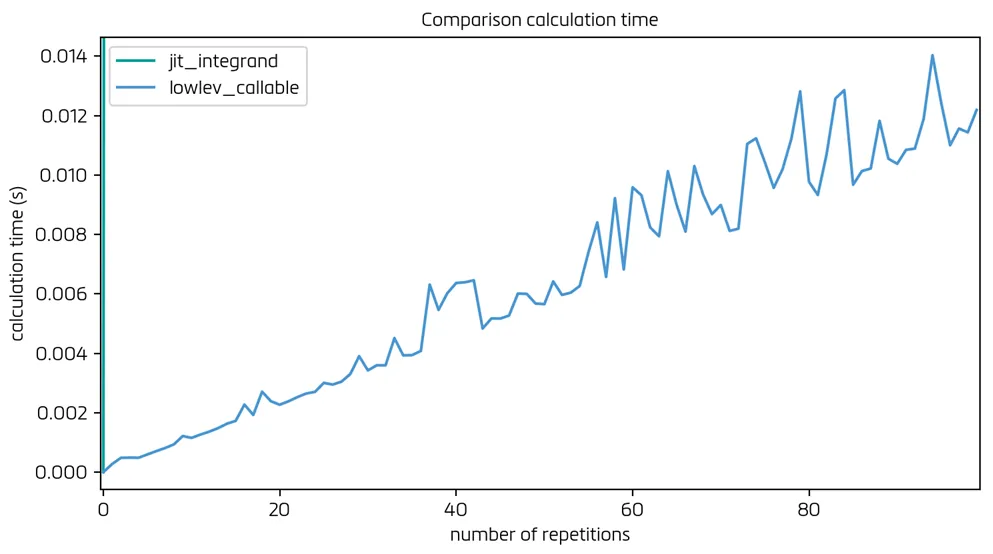
xx数组的形式打包)。如果有人能够从设计角度给出一些实现建议,那将非常好。坚持使用numba仍然是我的首选。谢谢! - moseguiLowLevelCallable(这会增加约一秒钟的总计算时间),然后使用更高效的积分迭代更快(这可以节省我约两秒钟的时间)。总的来说,我的整体计算时间减少了约一半!!(大约两秒钟而不是四秒钟)。非常感谢你! - mosegui