np.r_实现在numpy/lib/index_tricks.py文件中。这是纯Python代码,没有任何特殊编译的东西。所以它不会比使用concatenate、arange和linspace等等等效的方法更快。它只有在符合您的思维方式和需求时才有用。
在你的例子中,它只是节省了将标量转换为列表或数组的步骤:
In [452]: np.r_[0.0, np.array([1,2,3,4]), 0.0]
Out[452]: array([ 0., 1., 2., 3., 4., 0.])
同样的参数导致错误:
In [453]: np.concatenate([0.0, np.array([1,2,3,4]), 0.0])
...
ValueError: zero-dimensional arrays cannot be concatenated
增加 [] 后正确
In [454]: np.concatenate([[0.0], np.array([1,2,3,4]), [0.0]])
Out[454]: array([ 0., 1., 2., 3., 4., 0.])
hstack通过将所有参数传递给[atleast_1d(_m) for _m in tup] 来处理此问题:
In [455]: np.hstack([0.0, np.array([1,2,3,4]), 0.0])
Out[455]: array([ 0., 1., 2., 3., 4., 0.])
所以至少在简单的情况下,它与hstack最相似。
但是r_的真正用处在于当您想使用范围时。
np.r_[0.0, 1:5, 0.0]
np.hstack([0.0, np.arange(1,5), 0.0])
np.r_[0.0, slice(1,5), 0.0]
r_让你可以使用索引中常用的:语法,这是因为它实际上是一个带有__getitem__方法的类的实例。index_tricks在多个地方使用了这个编程技巧。
此外,它们还添加了其他功能。
当使用一个imaginary步长时,使用np.linspace扩展切片而不是np.arange。
np.r_[-1:1:6j, [0]*3, 5, 6]
产生:
array([-1. , -0.6, -0.2, 0.2, 0.6, 1. , 0. , 0. , 0. , 5. , 6. ])
文档中有更多详细信息。
我在https://dev59.com/eJffa4cB1Zd3GeqP_rXR#37625115中对许多切片进行了一些时间测试。
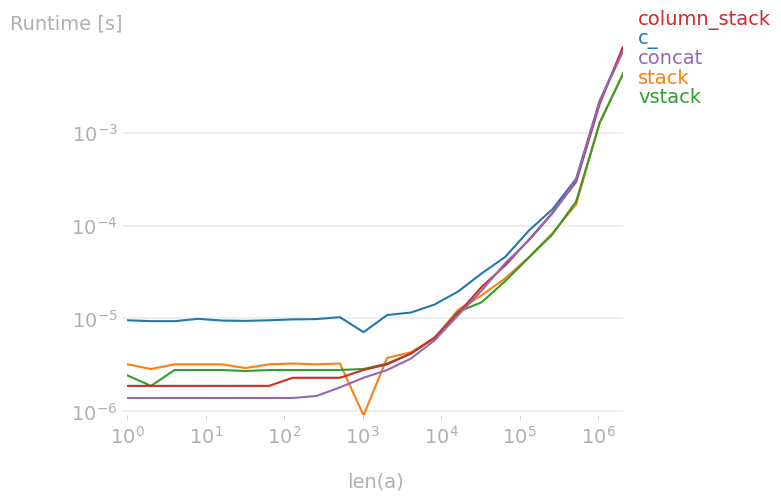
np.r_[1:5, 3:7]与np.concatenate(np.arange(....)相同速度。最终都会变成一个concatenate调用。 - hpaulj