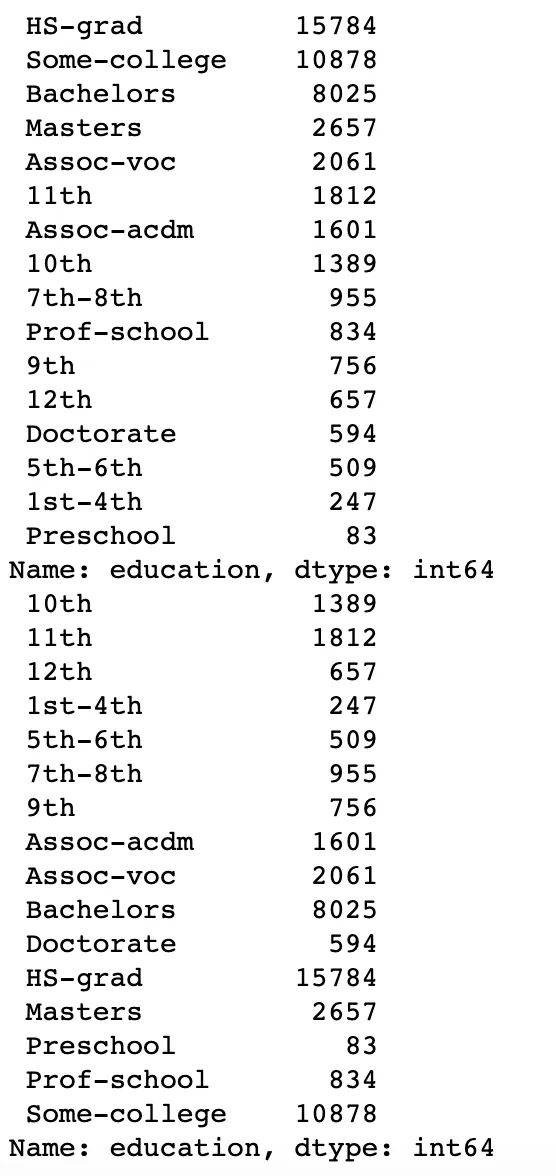
我需要按照预设的等级排序一个字符串变量(教育水平),以下是我写的代码。然而,它仍然使用字母表顺序排序(请查看附加的图片),我不知道出了什么问题。
education_rank = {' Bachelors':12, ' HS-grad':8, ' 11th':6, ' Masters':14, ' 9th':5, ' Some-college':11, ' Assoc-acdm':10, ' Assoc-voc':9, ' 7th-8th':4, ' Doctorate':15, ' Prof-school':13, ' 5th-6th':3, ' 10th':16, ' 1st-4th':2, ' Preschool':1, ' 12th':7}
fd_education = pd.value_counts(adult_data.education)
print(fd_education)
fd_education = fd_education.sort_index(level='education_rank')
print(fd_education)