我正在尝试计算按名称分组的列的季度移动平均值,并定义了一个Spark窗口函数规范,如下:
val wSpec1 = Window.partitionBy("name").orderBy("date").rowsBetween(-2, 0)
我的数据帧(DataFrame)如下所示:
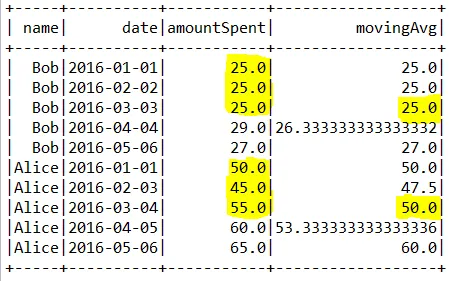
+-----+----------+-----------+------------------+
| name| date|amountSpent| movingAvg|
+-----+----------+-----------+------------------+
| Bob|2016-01-01| 25.0| 25.0|
| Bob|2016-02-02| 25.0| 25.0|
| Bob|2016-03-03| 25.0| 25.0|
| Bob|2016-04-04| 29.0|26.333333333333332|
| Bob|2016-05-06| 27.0| 27.0|
|Alice|2016-01-01| 50.0| 50.0|
|Alice|2016-02-03| 45.0| 47.5|
|Alice|2016-03-04| 55.0| 50.0|
|Alice|2016-04-05| 60.0|53.333333333333336|
|Alice|2016-05-06| 65.0| 60.0|
+-----+----------+-----------+------------------+
对于每个名称组,精确计算的第一个值都会被突出显示。我想用一些字符串,比如NULL替换前两个值。鉴于我对Spark/Scala的知识有限,我考虑从DataFrame中提取此列并在Scala中使用patch函数。然而,我无法弄清楚如何替换像第二个名称组开头这样的间隔处的值。以下是我的代码:
import com.datastax.spark.connector._
import org.apache.spark.SparkContext
import org.apache.spark.SparkContext._
import org.apache.spark.SparkConf
import org.apache.spark.sql._
import org.apache.spark.sql.types.StructType
import org.apache.spark.sql.types.StructField
import org.apache.spark.sql.types.StringType
import org.apache.spark.sql.types.IntegerType
import org.apache.spark.sql.types.DoubleType
import org.apache.spark.sql.expressions.Window
import org.apache.spark.sql.functions._
import org.apache.spark.sql.Row
import org.apache.spark.sql.types._
object Test {
def main(args: Array[String]) {
//val sparkSession = SparkSession.builder.master("local").appName("Test").config("spark.cassandra.connection.host", "localhost").config("spark.driver.host", "localhost").getOrCreate()
val sparkSession = SparkSession.builder.master("local").appName("Test").config("spark.cassandra.connection.host", "localhost").config("spark.driver.host", "localhost").getOrCreate()
val sc = sparkSession.sparkContext
val sqlContext = new org.apache.spark.sql.SQLContext(sc)
import sparkSession.implicits._
val customers = sc.parallelize(List(("Alice", "2016-01-01", 50.00),
("Alice", "2016-02-03", 45.00),
("Alice", "2016-03-04", 55.00),
("Alice", "2016-04-05", 60.00),
("Alice", "2016-05-06", 65.00),
("Bob", "2016-01-01", 25.00),
("Bob", "2016-02-02", 25.00),
("Bob", "2016-03-03", 25.00),
("Bob", "2016-04-04", 29.00),
("Bob", "2016-05-06", 27.00))).toDF("name", "date", "amountSpent")
import org.apache.spark.sql.expressions.Window
import org.apache.spark.sql.functions._
// Create a window spec.
val wSpec1 = Window.partitionBy("name").orderBy("date").rowsBetween(-2, 0)
val ls=customers.withColumn("movingAvg",avg(customers("amountSpent")).over(wSpec1))
ls.show()
}
}