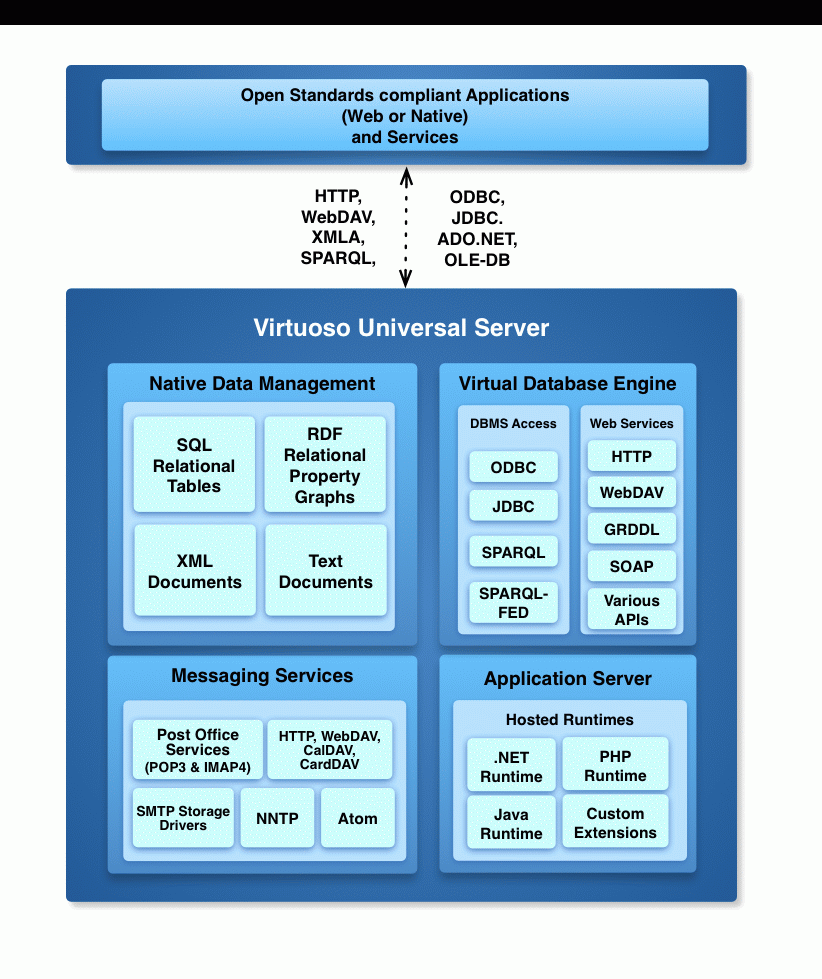
我目前正在调查Virtuoso,我很想知道本机RDF Quad Store和基于SQL的RDF Triple Store之间的区别,如此页面所示(向下滚动一点查看图表):http://virtuoso.openlinksw.com/dataspace/doc/dav/wiki/Main/VirtJenaProvider
我知道本机RDF Quad Store在底层使用传统的关系数据库,但它经过优化,可以更快地使用SPARQL进行查询。这让我感到困惑!因为我想知道SQL基础的RDF Triple存储现在是什么样的......
谢谢!
谢谢!
{kind=link}