PolynomialFeatures 会生成一个新矩阵,该矩阵包含给定次数的所有特征的多项式组合。
例如,对于二次项(degree 2),[a] 会被转换为 [1,a,a^2]。
您可以将输入数据的转换过程可视化为由 PolynomialFeatures 生成的矩阵。
from sklearn.preprocessing import PolynomialFeatures
a = np.array([1,2,3,4,5])
a = a[:,np.newaxis]
poly = PolynomialFeatures(degree=2)
a_poly = poly.fit_transform(a)
print(a_poly)
输出:
[[ 1. 1. 1.]
[ 1. 2. 4.]
[ 1. 3. 9.]
[ 1. 4. 16.]
[ 1. 5. 25.]]
你可以看到以[1,a,a^2]形式生成的矩阵。
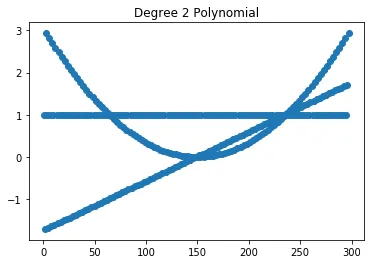
为了观察散点图上的多项式特征,让我们使用数字1-100。
import numpy as np
from sklearn.preprocessing import StandardScaler
from sklearn.preprocessing import PolynomialFeatures
a = np.arange(1,100,1)
a = a[:,np.newaxis]
scaler = StandardScaler()
a = scaler.fit_transform(a)
poly = PolynomialFeatures(degree=2)
a_poly = poly.fit_transform(a)
a_poly = a_poly.flatten()
xarr = np.arange(1,a_poly.size+1,1)
plt.scatter(xarr,a_poly)
plt.title("Degree 2 Polynomial")
plt.show()
输出:
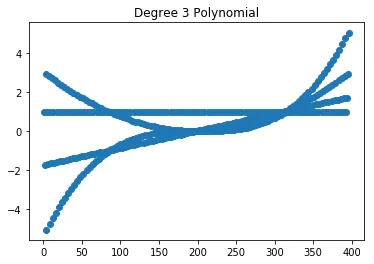
将度数更改为3,我们得到:
sklearn中默认的PolynomialFeatures包括所有的多项式组合。你可以添加interaction_only=True来排除像a^2, b^2, c^2这样的幂次。当然,如果你的模型表现更好,你也可以排除交互作用 -PolynomialFeatures是一种简单的方法来以某种人为的方式派生新特征。 - dimbc的位置是正确的。查看poly.get_feature_names(['a','b','c']),将会得到['1', 'a', 'b', 'c', 'a^2', 'a b', 'a c', 'b^2', 'b c', 'c^2']。 - Niko Pasanen