import os
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.pipeline import Pipeline
from sklearn.linear_model import LinearRegression
from sklearn.preprocessing import PolynomialFeatures
csv_path = os.path.join('', 'graph.csv')
graph = pd.read_csv(csv_path)
y = graph['y'].copy()
x = graph.drop('y', axis=1)
pipeline = Pipeline([('pf', PolynomialFeatures(2)), ('clf', LinearRegression())])
pipeline.fit(x, y)
predict = [[16], [20], [30]]
plt.plot(x, y, '.', color='blue')
plt.plot(x, pipeline.predict(x), '-', color='black')
plt.plot(predict, pipeline.predict(predict), 'o', color='red')
plt.show()
我的图表.csv:
x,y
1,1
2,2
3,3
4,4
5,5
6,5.5
7,6
8,6.25
9,6.4
10,6.6
11,6.8
产生的结果如下:
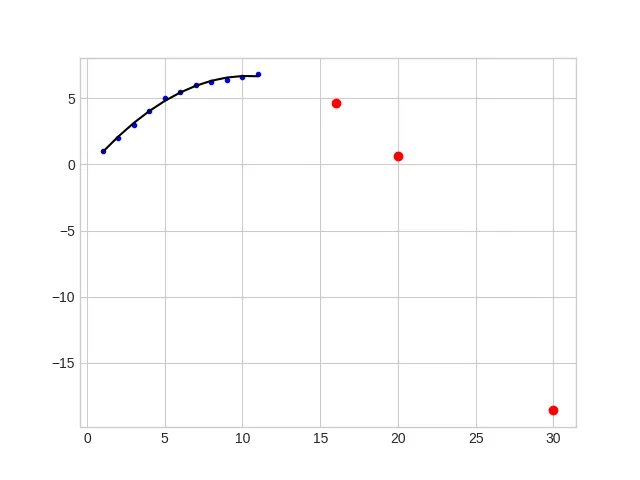
显然,它产生了错误的预测;对于每个 x,y 应该增加。
我错过了什么?我尝试改变度数,但改善效果不大。例如,当我使用 4 度时,y 增长得非常非常快。
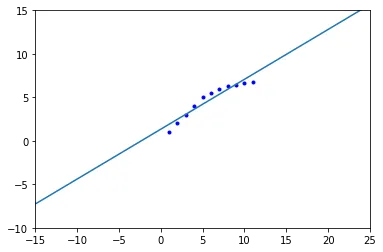
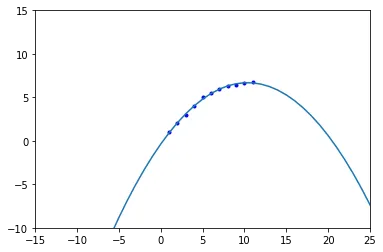
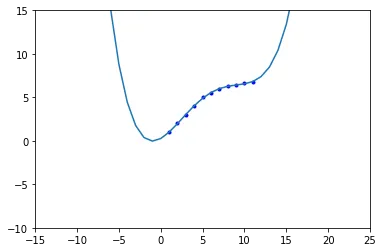
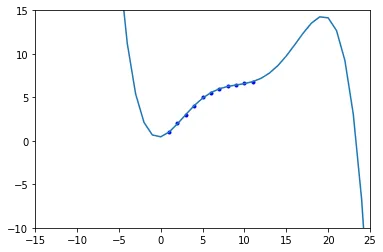

graph.csv文件中,这 11 个数据点是唯一的吗?还是还有其他的数据? - ranka47