我目前正在尝试使用Python中的sklearn实现分类中的K-FOLD交叉验证。我理解K-FOLD和交叉验证的基本概念。然而,我不明白cross_val_score是什么以及它是如何工作的,CV迭代在获取我们得到的分数数组中扮演着什么角色。下面是来自sklearn官方文档页面的示例。
**Example 1**
from sklearn import datasets, linear_model
from sklearn.model_selection import cross_val_score
diabetes = datasets.load_diabetes()
X = diabetes.data[:150]
y = diabetes.target[:150]
lasso = linear_model.Lasso()
print(cross_val_score(lasso, X, y, cv=3))
***OUPUT***
[0.33150734 0.08022311 0.03531764]
看一下示例1,输出在一个数组中生成了3个值。我知道当我们使用kfold时,n_split是生成折叠次数的命令。那么在这个示例中,cv是做什么的呢?
**My Code**
kf = KFold(n_splits=4,random_state=seed,shuffle=False)
print('Get_n_splits',kf.get_n_splits(X),'\n\n')
for train_index, test_index in kf.split(X):
print('TRAIN:', train_index, 'TEST:', test_index)
x_train, x_test = df.iloc[train_index], df.iloc[test_index]
y_train, y_test = df.iloc[train_index], df.iloc[test_index]
print('\n\n')
# use train_test_split to split into training and testing data
x_train, x_test, y_train, y_test = cross_validation.train_test_split(X, y,test_size=0.25,random_state=0)
# fit / train the model using the training data
clf = BernoulliNB()
model = clf.fit(x_train, y_train)
y_predicted = clf.predict(x_test)
scores = cross_val_score(model, df, y, cv=4)
print('\n\n')
print('Bernoulli Naive Bayes Classification Cross-validated Scores:', scores)
print('\n\n')
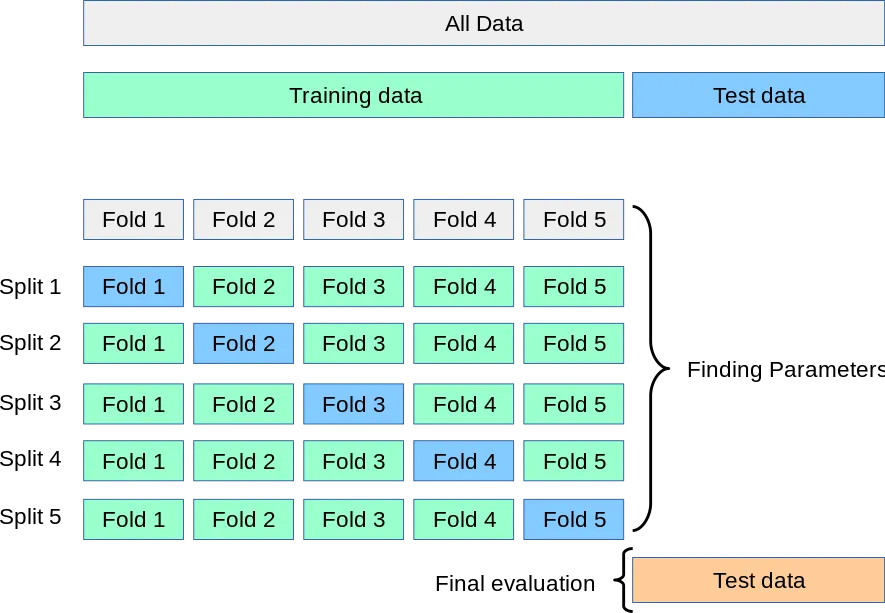
看我的代码,我正在使用4倍交叉验证对伯努利朴素贝叶斯分类器进行评分,并在score中使用cv=4,如下所示: scores = cross_val_score(model, df, y, cv=4) 以上一行给我提供了一个包含4个值的数组。但是,如果我将其更改为cv=8,如下所示: scores = cross_val_score(model, df, y, cv=8) 那么将生成一个包含8个值的数组作为输出。那么cv在这里有什么作用呢?
我已经反复阅读了文档并搜索了许多网站,但由于我是新手,我真的不理解cv的作用和得分是如何生成的。
非常感谢您的任何帮助。
提前致谢。
{kind=link}
cross_val_score在你的所有示例中执行完全相同的操作。它接受特征df和目标y,将其分成 k 折(即 cv 参数),在 (k-1) 折上进行拟合并在最后一折上进行评估。它会执行这个过程 k 次,这就是为什么你的输出数组中有 k 个值的原因。 - Troyfor train_index, test_index in kf.split(X): print('TRAIN:', train_index, 'TEST:', test_index) x_train, x_test = df.iloc[train_index], df.iloc[test_index] y_train, y_test = df.iloc[train_index], df.iloc[test_index])将df分成4个折叠,然后训练4个模型,其中每个折叠都用作测试集。那么cv是否以与for循环中df拆分相同的方式拆分df,还是不同?我询问的目的是重新验证每个折叠的准确性。此外,确认一下cross_val_score是否调用模型的score属性? - Stevi G