大家好,我有些困惑如何使用 sklearn.calibration.CalibratedClassifierCV 的输出。
我已经使用这种方法校准了我的二元分类器,并且结果得到了很大改善。然而,我不确定如何解释结果。 sklearn指南 指出,在校准之后,
predict_proba方法的输出可以直接解释为置信度水平。例如,一个良好校准的(二元)分类器应该对样本进行分类,使得在它给予预测概率接近0.8的样本中,大约有80%属于正类别。
现在,我想通过将模型预测标签设置为 True 的截断值设为0.6来减少误报率。如果没有校准,我会简单地使用 my_model.predict_proba() > .6。
然而,似乎在校准之后,predict_proba 的含义已经发生改变,所以我不确定是否还能这样做。
从快速测试结果来看,predict 和 predict_proba 遵循了我在校准之前所预期的相同逻辑。以下是代码输出:
pred = my_model.predict(valid_x)
proba= my_model.predict_proba(valid_x)
pd.DataFrame({"label": pred, "proba": proba[:,1]})
以下是翻译的结果:
如下所示:
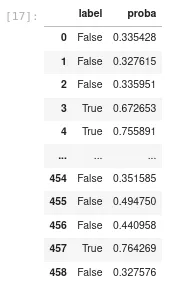
以上意思是:如果某个样本的概率超过0.5,则该样本被分类为“True”,如果低于0.5,则被分类为“False”。
请问,经过校准后,我是否仍然可以使用 predict_proba 应用不同的截断值来标识我的标签?
2 https://scikit-learn.org/stable/modules/calibration.html#calibration