我有一堆由用户输入的字符串,这些字符串是不同评论串联在一起的。如果有多天的评论,他们有时会输入日期。我正在尝试找到一种方法来分离每个日期和相应的评论。文本评论可能像这样:
raw_text = ['3/30: The dog is red. 4/01: The dog is blue', 'there is a green door', '3-25:Foobar baz']
I would like to transform that text to:
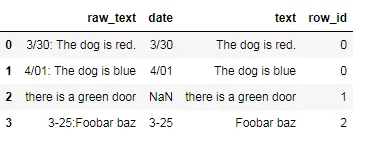
df = pd.DataFrame([[0,'3/30','The dog is red.'],[0,'4/01','The dog is blue'],[1,np.nan,'there is a green door'],[2,'3-25','Foobar baz']],columns = 'row_id','date','text')
print(df)
row_id date text
0 0 3/30 The dog is red.
1 0 4/01 The dog is blue
2 1 NaN there is a green door
3 2 3-25 Foobar baz
我认为我需要做的是找到分号,然后回溯到分号之前的第一个数字来确定日期(有时使用 / 分隔,有时使用 -)。
如果能提供使用正则表达式的方法将会非常感激——这已经超出了我的简单切割/查找知识范围。
谢谢!