我有一个具体的密度函数,想要根据密度函数的表达式生成随机变量。
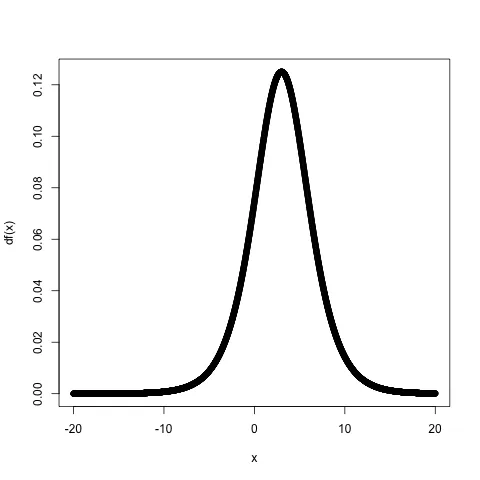
例如,密度函数是:
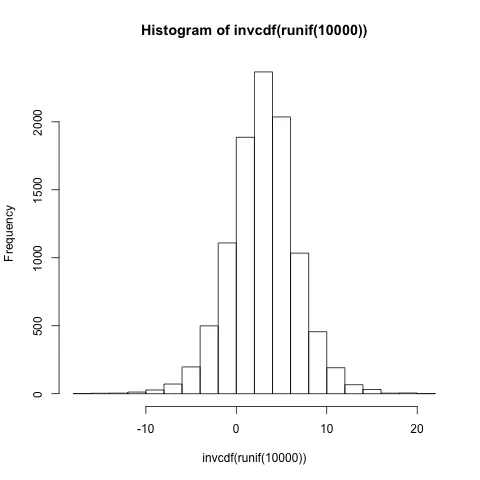
从这个表达式中,我想要生成1000个具有相同分布的随机元素。
我知道我应该使用反向抽样方法。为此,我使用我的概率密度函数的累积分布函数,计算如下:
这个想法是生成均匀分布的样本,然后使用我的累积分布函数进行映射得到一个反向映射结果。就像这样:
然后使用所需的随机变量数量调用它以生成随机数。
这个方法正确吗?
例如,密度函数是:
df=function(x) { - ((-a1/a2)*exp((x-a3)/a2))/(1+exp((x-a3)/a2))^2 }
从这个表达式中,我想要生成1000个具有相同分布的随机元素。
我知道我应该使用反向抽样方法。为此,我使用我的概率密度函数的累积分布函数,计算如下:
cdf=function(x) { 1 - a1/(1+exp((x-a3)/a2))
这个想法是生成均匀分布的样本,然后使用我的累积分布函数进行映射得到一个反向映射结果。就像这样:
random.generator<-function(n) sapply(runif(n),cdf)
然后使用所需的随机变量数量调用它以生成随机数。
random.generator(1000)
这个方法正确吗?