给定以下概率分布:
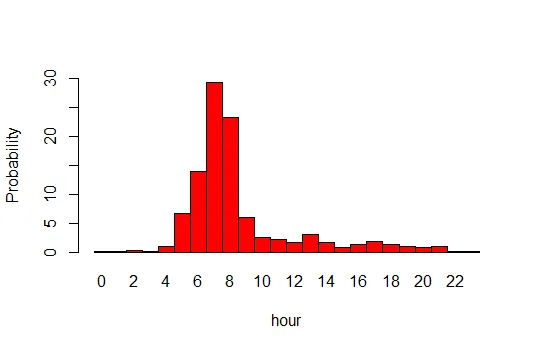
x坐标表示小时数,y坐标表示每小时的概率。
问题是如何生成一组符合该概率分布的1000个随机数据?
sample。您可以指定额外的参数prob到sample,它指定了每个元素的概率。例如,sample(1:22,1000,replace=TRUE,prob=c(
0,1,0,3,7,14,30,24,5,3,3,2,4,3,1,2,3,2,2,2,1,0
)
(用你的条形图高度替换那个数字字符串)。prob参数不必总和为1,R会为您重新规范化它。
R可能会生成一个警告,指出它正在使用“沃克别名方法”,并且结果与旧版本的R不可比较。这是正常的,不用担心。
distribution <- c( 2, 4, 4, rep(5, 7), rep(6, 14), rep(7, 29),
rep(8, 23), rep(9, 7), rep(10, 4), rep(11, 3))
sample(distribution, 1000, replace=TRUE)
我在11之后留下了一些值,可能没有完全准确地读取所有的值,但你可以看到这个想法。根据数据格式,分布向量可能更容易生成。