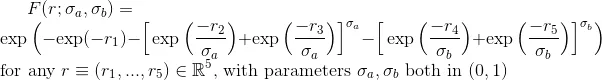您在#3下的链接提供了解决方案的线索。它解释了当您拥有PDF时的双变量情况。在这里,我们将扩展到任意维度的情况,当您拥有CDF时。
因此,该过程如下:
- 计算r1的边缘CDF。
- 使用此边缘CDF进行随机抽样(您发布的另一个链接解释了如何执行此操作)。
- 计算在给定r1的情况下r2的边缘CDF。
- 使用此边缘CDF进行随机抽样。
- 计算在给定r1和r2的情况下r3的边缘CDF。
- 等等。您看到这会导致什么结果。
请注意,如果您有一个PDF文件,则计算边际分布需要对其余变量进行积分。因此,对于
r1的边缘分布需要对
r2..
r5进行积分,给定
r1的
r2的边缘分布需要对
r3..
r5进行积分,以此类推。
当你有一个CDF时,计算边缘分布是微不足道的,因为它已经集成了PDF:
r1的边缘分布是
F(
x,∞,∞,∞,∞)。然而,给定一个或多个变量的边缘分布需要不同的方法:给定
r1的
r2的边缘分布需要沿着
r1进行微分,给定
r1和
r2的
r3的边缘分布需要沿着
r1和
r2进行微分,等等。
可能可以通过解析法获得这些导数(这将是更有效的解决方案)。在这里,我们使用有限差分导数逼近(这使得插入任何CDF更容易)。
让我们看一些MATLAB代码:
sigma_a = 0.5;
sigma_b = 0.3;
F = @(r1,r2,r3,r4,r5)exp(-exp(-r1) - (exp(-r2/sigma_a)+exp(-r3/sigma_a)).^sigma_a ...
- (exp(-r4/sigma_b)+exp(-r5/sigma_b)).^sigma_b);
lims = [-5,10];
N = 1000;
values = zeros(N,5);
for n=1:N
values(n,:) = sample_random(F,5,lims);
end
在这里,我选择了一些随机的值作为sigma_a和sigma_b,并使用它们来定义一个由5个变量r1..r5组成的函数F。我发现PDF的定义域在所有维度上都相同,我找到了一个比实际需要稍微大一点的区域(lims)。接下来,我通过调用sample_random从分布F中获取1000个随机样本:
function r = sample_random(F,N,lims)
delta = diff(lims)/10000;
x = linspace(lims(1),lims(2),300);
r = inf(1,N);
for ii = 1:N
marginal = get_marginal(F,r,ii,x,delta);
p = rand * marginal(end);
[~,I] = unique(marginal);
r(ii) = interp1(marginal(I),x(I),p);
end
delta是有限差分逼近导数所使用的距离。 x表示F中任意一个维度上的样本点。
我们首先将r定义为向量[inf,inf,inf,inf,inf],我们将其用作样本位置,在函数的末尾,它将包含从我们的分布中抽取的随机值。
接下来,我们循环遍历5个维度,在每次迭代中,我们根据已经选择的前几个维度的值(已经被选定)对维度ii的边缘分布进行采样。函数get_marginal如下所示。我们在0到这个边缘CDF的最大值之间选择一个随机值(注意,随着我们为每个维度选择r的值,最大值会减小;当ii==1时,最大值为1),并使用这个随机值插值到反向采样的边缘CDF中(反向简单地意味着交换x和y)。我需要从marginal中删除重复的值,因为它成为interp1中的x,而这个函数要求x值是唯一的。
最后,函数get_marginal:
function marginal = get_marginal(F,r,ii,x,delta)
N = length(r);
marginal = zeros(size(x));
for jj=0:2^(ii-1)-1
rr = flip(dec2bin(jj,N)-'0');
sign = mod(sum(rr,2),2);
if sign == 0
sign = 1;
else
sign = -1;
end
args = num2cell(r - delta * rr);
args{ii} = x;
marginal = marginal + sign * F(args{:});
end
这段内容有些复杂。它沿着给定的维度“ii”对CDF进行采样,在点“x”处给出固定值“r(1:ii-1)”。
计算偏导数会带来一些复杂性。如果我们要计算任何一个维度的边际分布,而没有选择任何固定值,我们只需简单地执行以下操作:
marginal = F(inf,x,inf,inf,inf)
选定一个值后,我们会执行
marginal = F(r1,x,inf,inf,inf) - F(r1-delta,x,inf,inf,inf);
(这是沿第一维度的偏导数近似值)。
get_marginal 中的代码为 ii-1 个固定值执行此操作。这需要对每个固定值两次对 F 进行采样,以及对每个 delta 移位组合,共计 n^2 次操作(对于 n 个固定值)。dec2bin 的作用是获取所有这些组合。sign 决定是否从累加器中加上或减去给定的样本。args 是一个包含函数 F 的 5 个参数的单元数组,元素 1:ii-1 是固定值,元素 ii 设置为 x,元素 ii+1:N 是 inf。
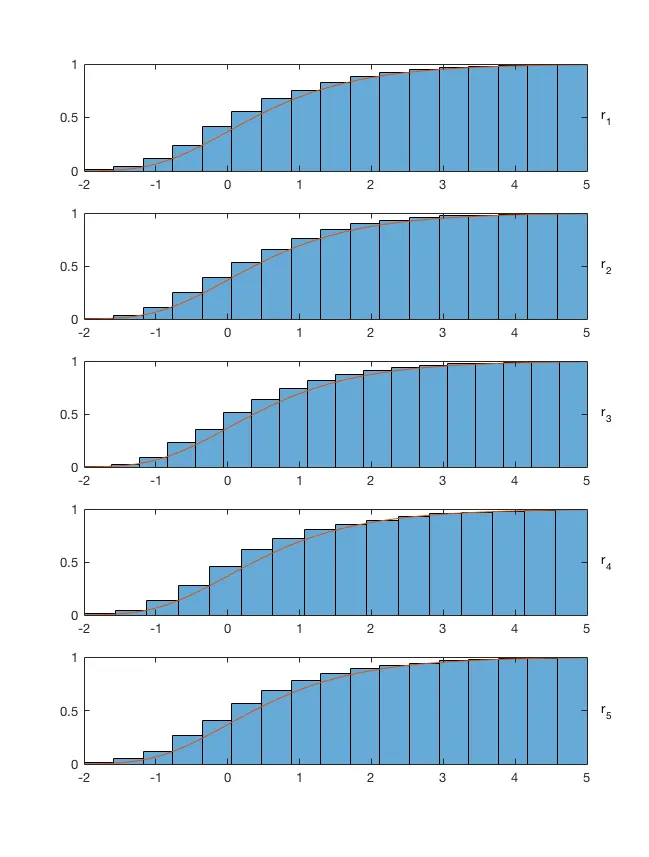
最后,我绘制数据集
values的边际分布(其中包含从CDF中随机抽取的1000个元素),并与CDF的边际分布叠加以验证所有内容是否正确:
lims = [-2,5];
x = linspace(lims(1),lims(2),300);
figure
for ii=1:5
subplot(5,1,ii)
histogram(values(:,ii),'normalization','cdf','BinLimits',lims)
hold on
args = num2cell(inf(1,5));
args{ii} = x;
plot(x,F(args{:}))
text(5.2,0.5,['r_',num2str(ii)])
end