使用groupby方法和apply方法,返回一个Series以重命名列名
使用groupby方法的apply函数执行聚合操作:
- 重命名列名
- 允许列名中有空格
- 可按任意顺序排序返回的列
- 允许列之间的交互
- 返回单层索引而不是多层索引
实现方法如下:
- 创建一个自定义函数并将其传递给apply函数
- 该自定义函数作用于每个分组的DataFrame数据
- 返回一个Series
- Series的索引将成为新的列名
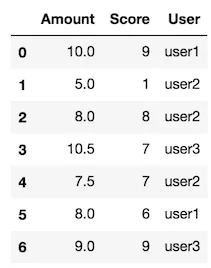
创建虚假数据
df = pd.DataFrame({"User": ["user1", "user2", "user2", "user3", "user2", "user1", "user3"],
"Amount": [10.0, 5.0, 8.0, 10.5, 7.5, 8.0, 9],
'Score': [9, 1, 8, 7, 7, 6, 9]})
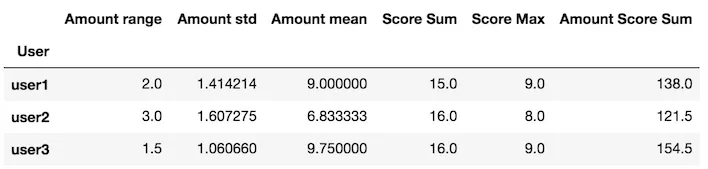
创建一个返回Series的自定义函数
my_agg内的变量x是一个DataFrame。
def my_agg(x):
names = {
'Amount mean': x['Amount'].mean(),
'Amount std': x['Amount'].std(),
'Amount range': x['Amount'].max() - x['Amount'].min(),
'Score Max': x['Score'].max(),
'Score Sum': x['Score'].sum(),
'Amount Score Sum': (x['Amount'] * x['Score']).sum()}
return pd.Series(names, index=['Amount range', 'Amount std', 'Amount mean',
'Score Sum', 'Score Max', 'Amount Score Sum'])
将此自定义函数传递给groupby apply方法
df.groupby('User').apply(my_agg)
缺点是这个函数比cythonized聚合的agg方法慢得多。
使用字典与groupby的agg方法
由于其复杂性和含糊不清的特性,已经删除了使用字典的方法。 关于如何改进这一功能,现在正在github上进行持续讨论。 在这里,您可以在groupby调用之后直接访问聚合列。 只需传递您希望应用的所有聚合函数的列表即可。
df.groupby('User')['Amount'].agg(['sum', 'count'])
输出
sum count
User
user1 18.0 2
user2 20.5 3
user3 10.5 1
仍然可以使用词典来明确指定不同列的不同聚合方式,就像这里如果有另一个名为Other的数字列一样。
df = pd.DataFrame({"User": ["user1", "user2", "user2", "user3", "user2", "user1"],
"Amount": [10.0, 5.0, 8.0, 10.5, 7.5, 8.0],
'Other': [1,2,3,4,5,6]})
df.groupby('User').agg({'Amount' : ['sum', 'count'], 'Other':['max', 'std']})
输出
Amount Other
sum count max std
User
user1 18.0 2 6 3.535534
user2 20.5 3 5 1.527525
user3 10.5 1 4 NaN