我目前正在开发某种OCR(光学字符识别)系统。我已经编写了一个脚本来提取文本中的每个字符并清除(大部分)的不规则性。我也知道字体。现在我拥有的图像示例为:
M(http://i.imgur.com/oRfSOsJ.png(字体)和http://i.imgur.com/UDEJZyV.png(扫描))
K(http://i.imgur.com/PluXtDz.png(字体)和http://i.imgur.com/TRuDXSx.png(扫描))
C(http://i.imgur.com/wggsX6M.png(字体)和http://i.imgur.com/GF9vClh.png(扫描))
对于所有这些图像,我已经有了一种二进制矩阵(黑色为1,白色为0)。我现在想知道是否有一种数学投影式公式来查看这些矩阵之间的相似性。我不想依赖于库,因为这不是给我的任务。
我知道这个问题可能有点模糊,也有类似的问题,但我正在寻找方法,而不是包,到目前为止我没有找到任何关于方法的评论。这个问题之所以模糊,是因为我真的没有开始的地方。我想做的事情实际上在维基百科上描述:
Matrix matching是一种按像素逐个比较图像与存储字形的技术,也称为“模式匹配”或“模式识别”[9]。这种技术依赖于正确地将输入字形从图像中分离出来,并且存储的字形在类似字体和相同比例尺度下。该技术最适用于打印文字,遇到新字体时效果不佳。这是早期基于物理光电池的OCR直接实现的技术。http://en.wikipedia.org/wiki/Optical_character_recognition#Character_recognition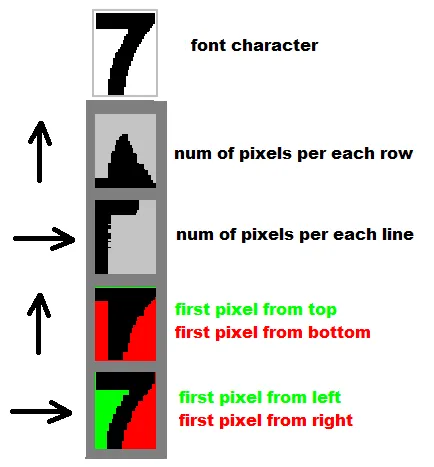
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}