我有一个数据框,其中每行代表时间,每列代表个体。我希望将其高效地转换为pandas中的长格式面板数据格式,因为数据框相当大。我希望避免循环。以下是一个示例:给定以下数据框:
id 1 2
date
20150520 3.0 4.0
20150521 5.0 6.0
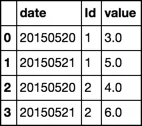
应该被转化为:
date id value
20150520 1 3.0
20150520 2 4.0
20150520 1 5.0
20150520 2 6.0
由于数据量很大,速度对我而言非常重要。如果需要取舍,我更喜欢速度而不是优雅。虽然我怀疑是否缺少了一个相当简单的函数,但 pandas 应该能够处理它。有什么建议吗?