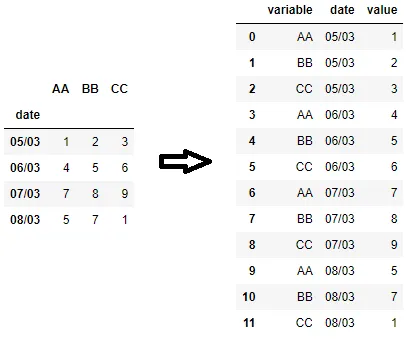
假设我在pandas中有以下数据框:
AA BB CC
date
05/03 1 2 3
06/03 4 5 6
07/03 7 8 9
08/03 5 7 1
我想将它转换为以下内容:
AA 05/03 1
AA 06/03 4
AA 07/03 7
AA 08/03 5
BB 05/03 2
BB 06/03 5
BB 07/03 8
BB 08/03 7
CC 05/03 3
CC 06/03 6
CC 07/03 9
CC 08/03 1
我该怎么做?
将数据从宽格式转换为长格式的原因是,下一阶段我想根据日期和初始列名(AA、BB、CC)将此数据框与另一个数据框合并。