一个关于Seaborn / Pandas的新手问题:我有一个Facebook页面帖子数据的电子表格,看起来像这样(前20行):
| Name | ID | Type | Date | Shares | Comments | Reactions | Engagement |
|------------------------|-----------------|-----------|------------------|--------|----------|-----------|------------|
| Herman Toothrot's Page | 201295459914847 | link | 13/05/2020 09:00 | 61 | 39 | 610 | 710 |
| Guybrush's Page | 167959249906191 | link | 13/05/2020 09:04 | 4 | 27 | 481 | 512 |
| Elaine's Page | 187202271820522 | album | 13/05/2020 09:12 | 0 | 3 | 96 | 99 |
| Elaine's Page | 187202271820522 | album | 13/05/2020 09:14 | 1 | 14 | 426 | 441 |
| Elaine's Page | 187202271820522 | photo | 13/05/2020 09:20 | 3 | 8 | 158 | 169 |
| Herman Toothrot's Page | 201295459914847 | link | 13/05/2020 09:20 | 26 | 101 | 508 | 635 |
| Elaine's Page | 187202271820522 | undefined | 13/05/2020 09:23 | 1 | 11 | 109 | 121 |
| Elaine's Page | 187202271820522 | photo | 13/05/2020 09:28 | 2 | 257 | 987 | 1246 |
| Herman Toothrot's Page | 201295459914847 | photo | 13/05/2020 09:30 | 1 | 0 | 178 | 179 |
| Elaine's Page | 187202271820522 | photo | 13/05/2020 09:31 | 3 | 6 | 162 | 171 |
| Elaine's Page | 187202271820522 | photo | 13/05/2020 09:38 | 44 | 143 | 4294 | 4481 |
| Elaine's Page | 187202271820522 | photo | 13/05/2020 09:39 | 7 | 79 | 631 | 795 |
| Herman Toothrot's Page | 201295459914847 | link | 13/05/2020 09:40 | 3 | 0 | 104 | 107 |
| Elaine's Page | 187202271820522 | photo | 13/05/2020 09:45 | 0 | 3 | 76 | 79 |
| Elaine's Page | 187202271820522 | photo | 13/05/2020 09:45 | 20 | 78 | 1455 | 1553 |
| Elaine's Page | 187202271820522 | photo | 13/05/2020 09:46 | 7 | 321 | 1847 | 2175 |
| Guybrush's Page | 167959249906191 | link | 13/05/2020 09:46 | 4 | 2 | 311 | 317 |
| Elaine's Page | 187202271820522 | photo | 13/05/2020 09:50 | 2 | 29 | 777 | 808 |
| Elaine's Page | 187202271820522 | link | 13/05/2020 09:53 | 0 | 0 | 115 | 115 |
| Herman Toothrot's Page | 201295459914847 | link | 13/05/2020 10:00 | 143 | 255 | 10211 | 10609 |
实际数据集跨越多天。
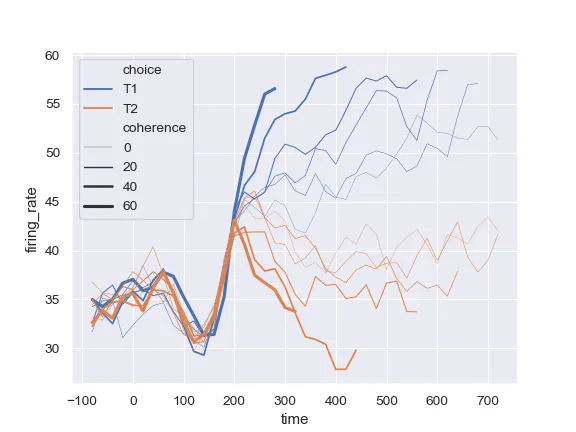
我想制作一个 Seaborn 折线图,以时间为 X 轴(“日期”),然后按天计算帖子数量作为 Y 轴。
然后,我想将其中一个数字变量设置为 SIZE 参数,并通过 HUE 分离“名称”中的页面。
因此,最终结果将类似于此 Seaborn 教程示例。
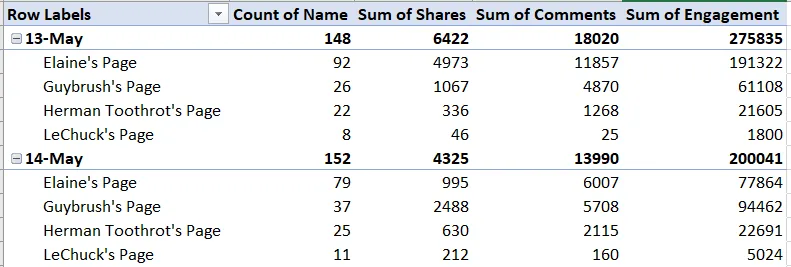
我知道这需要进行重新采样(或某种分组?)按天创建每个页面的汇总数据存储桶,就像在此Excel透视表中所示:
我以为我已经有所进展,
facebook_dataframe.groupby(["Name", "Date", "Reactions"], as_index=False)["Engagement"].sum()
...但我不想只按参与度(或任何一个变量)进行求和,并且我希望能够按天绘制图表。
我尝试过按天重新采样数据框,但最终得到的是显示计数或总和的系列,而我想要的是一些天的桶,其中所有数字变量都完好无损(如上述数据透视表所示)。
我希望这很清楚。我知道所提供的20个样本行都在同一天内,但如果任何建议解决方案可以改为按分钟重新采样,那么方法将是相同的吗?非常感谢任何帮助。