仔细观察,您链接的图表由
许多,许多,许多点而非线组成。
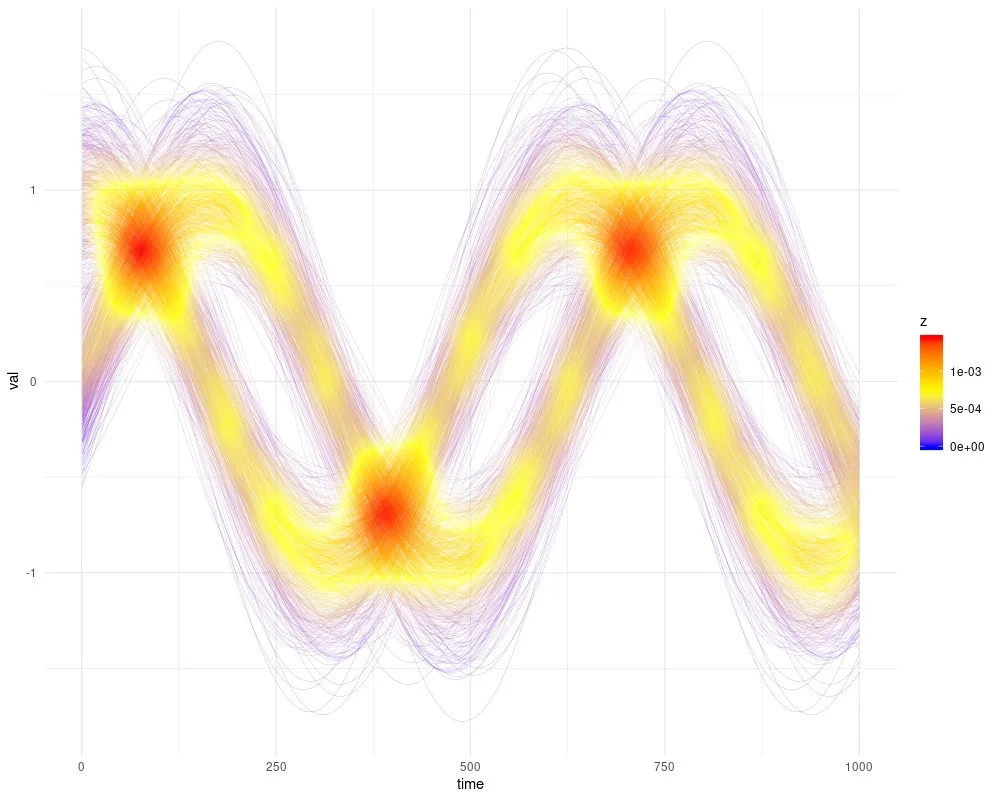
ggpointdensity软件包进行类似的可视化。请注意,由于有许多数据点,存在相当多的性能问题。我正在使用开发人员版本,因为它包含
method参数,允许使用不同的平滑估计器,并且明显有助于更好地处理更大的数字。也有CRAN版本。
您可以使用
adjust参数调整平滑度。
我已经增加了您代码的x间隔密度,使其看起来更像线条。虽然在图中稍微减少了“线”的数量。
library(tidyverse)
library(ggpointdensity)
set.seed(1)
gen.dat <- function(key) {
c <- sample(seq(0.1,1, by = 0.1), 1)
time <- seq(c*pi,length.out=500)
val <- sin(time)
time = seq(0.02,100,0.1)
data.frame(time,val,key)
}
dat <- lapply(seq(1, 1000), gen.dat) %>% bind_rows()
ggplot(dat, aes(time, val)) +
geom_pointdensity(size = 0.1, adjust = 10)

由 reprex包 (v0.3.0) 于2020年03月19日创建
更新
感谢user Robert Gertenbach提供了一些更有趣的样本数据。以下是在这些数据上建议使用ggpointdensity的方法:
library(tidyverse)
library(ggpointdensity)
gen.dat <- function(key) {
has_offset <- runif(1) > 0.5
time <- seq(1, 1000, length.out = 1000)
val <- sin(time / 100 + rnorm(1, sd = 0.2) + (has_offset * 1.5)) *
rgamma(1, 20, 20)
data.frame(time,val,key)
}
dat <- lapply(seq(1,1000), gen.dat) %>% bind_rows()
ggplot(dat, aes(time, val, group=key)) +stat_pointdensity(geom = "line", size = 0.05, adjust = 10) + scale_color_gradientn(colors = c("blue", "yellow", "red"))

本文创建于2020年3月24日,使用reprex包(v0.3.0)
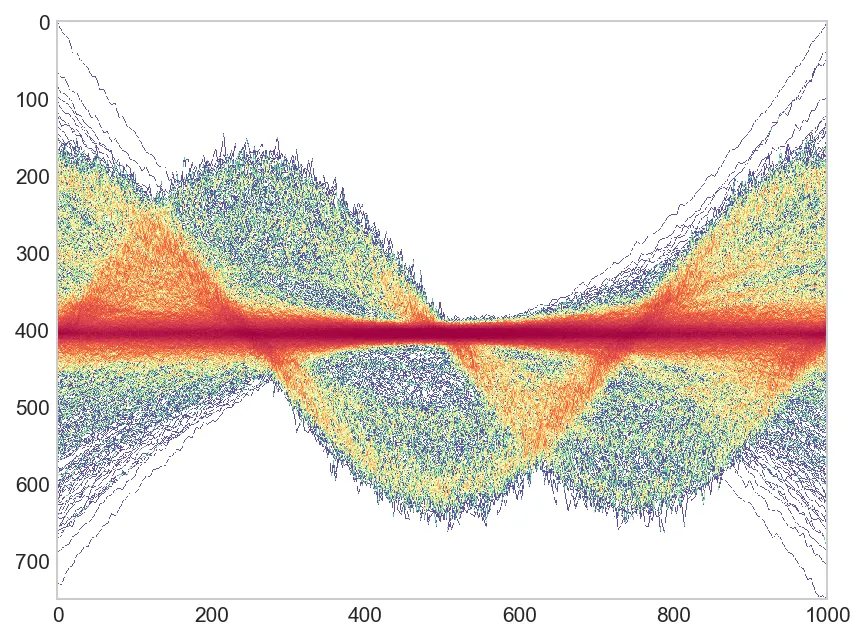
ggplot(dat, aes(time, val, group=key)) +stat_pointdensity(geom = "line", size = 0.05, adjust = 10) + scale_color_gradientn(colors = c("blue", "yellow", "red")),结果非常好看! - Robin Gertenbach