在Excel表格中,我有两列包含大量数字。
但是当我用
这两列以科学计数法的指数形式打印出来。
我该如何摆脱这种格式?
谢谢
Pandas输出
但是当我用
read_excel()读取Excel文件并显示数据框时,这两列以科学计数法的指数形式打印出来。
我该如何摆脱这种格式?
谢谢
Pandas输出
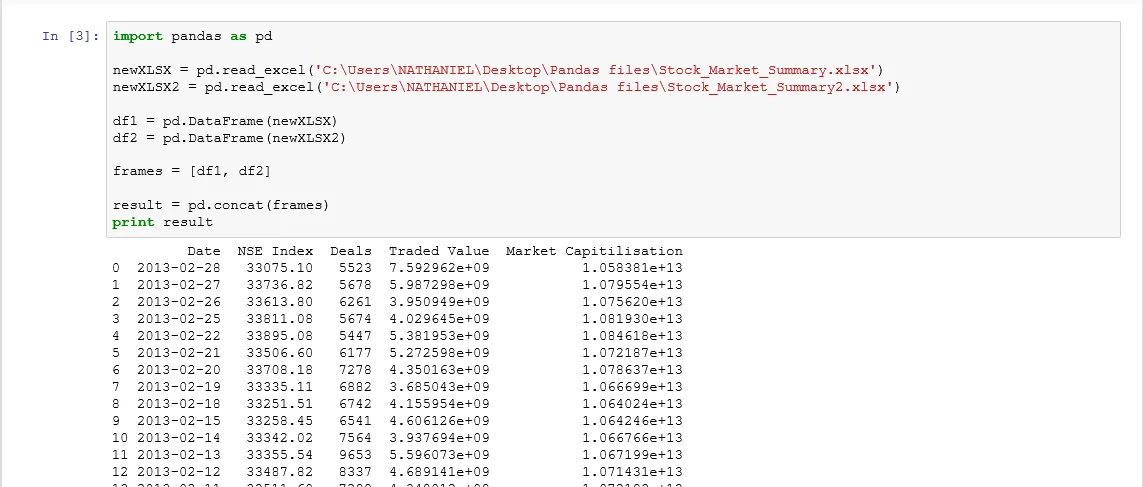
read_excel()读取Excel文件并显示数据框时,
科学计数法的应用是通过pandas的显示选项来控制的:
pd.set_option('display.float_format', '{:.2f}'.format)
df = pd.DataFrame({'Traded Value':[67867869890077.96,78973434444543.44],
'Deals':[789797, 789878]})
print(df)
Traded Value Deals
0 67867869890077.96 789797
1 78973434444543.44 789878
如果这仅仅是为了呈现效果,您可以按列将数据转换为字符串进行格式化:
df = pd.DataFrame({'Traded Value':[67867869890077.96,78973434444543.44],
'Deals':[789797, 789878]})
df
Deals Traded Value
0 789797 6.786787e+13
1 789878 7.897343e+13
df['Deals'] = df['Deals'].apply(lambda x: '{:d}'.format(x))
df['Traded Value'] = df['Traded Value'].apply(lambda x: '{:.2f}'.format(x))
df
Deals Traded Value
0 789797 67867869890077.96
1 789878 78973434444543.44
一种更简单的替代方法是在代码顶部加入以下行,它将仅格式化浮点数:
pd.options.display.float_format = '{:.2f}'.format
display.precision,但它似乎只影响小数部分,我想要影响整数部分。 - Nathaniel Babalola