我有两种不同情况下的F1和AUC得分。
模型1:精度:85.11 召回率:99.04 F1值:91.55 AUC值:69.94
模型2:精度:85.1 召回率:98.73 F1值:91.41 AUC值:71.69
我的主要目的是正确预测阳性案例,即减少假阴性案例(FN)。我应该使用F1值并选择模型1还是使用AUC值并选择模型2。谢谢。
我有两种不同情况下的F1和AUC得分。
模型1:精度:85.11 召回率:99.04 F1值:91.55 AUC值:69.94
模型2:精度:85.1 召回率:98.73 F1值:91.41 AUC值:71.69
我的主要目的是正确预测阳性案例,即减少假阴性案例(FN)。我应该使用F1值并选择模型1还是使用AUC值并选择模型2。谢谢。
一般而言,每当你想比较 ROC AUC 和 F1 Score 时,可以将其看作是基于以下模型性能的比较:
[Sensitivity vs (1-Specificity)] VS [Precision vs Recall]
请注意敏感度和召回率是相同的指标。
现在我们需要直观地理解什么是特异性、精确性和召回率(敏感度)!
特异性:由以下公式给出:
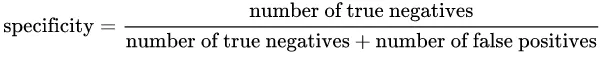
 直观地说,如果我们有一个100%精确的模型,那意味着它可以捕捉到所有True Positive,但没有False Positive。
直观地说,如果我们有一个100%精确的模型,那意味着它可以捕捉到所有True Positive,但没有False Positive。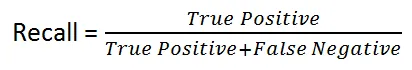
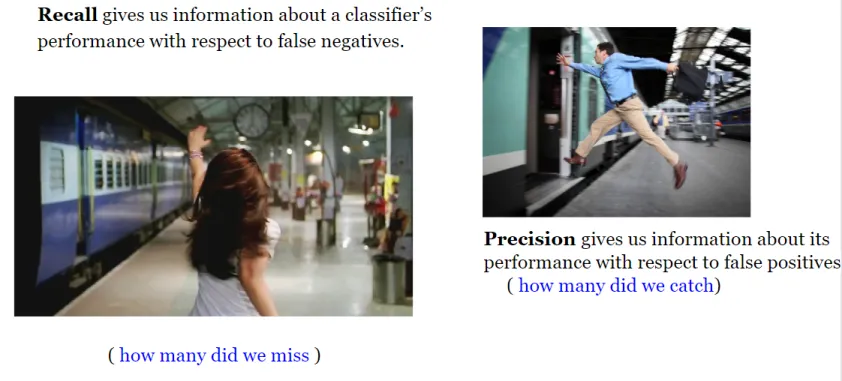
它由以下公式给出:
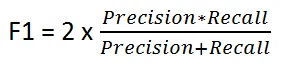
F1分数在精确度和召回率之间保持平衡。当存在不均匀的类分布时,我们使用它,因为精确度和召回率可能会给出误导性的结果!
因此,我们使用F1分数作为精确度和召回率数字之间的比较指标!
它比较了灵敏度与(1-特异性),换句话说,比较了真阳性率与假阳性率。
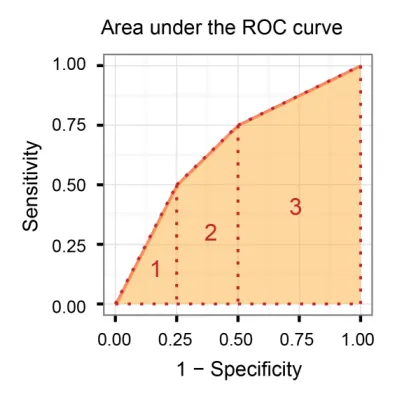
因此,AUROC越大,真正阳性和真正阴性之间的区别就越大!
一般来说,ROC适用于许多不同的阈值级别,因此它具有许多F分数值。F1分数适用于ROC曲线上的任何特定点。
您可以将其视为在特定阈值值上的精确度和召回率的度量,而AUC是ROC曲线下的面积。为了使F分数高,精确度和召回率都应该高。
因此,当您在正负样本之间存在数据不平衡时,应始终使用F1分数,因为ROC 平均所有可能的阈值!
进一步阅读:
信用卡欺诈:如何处理高度不平衡的类别,以及为什么不应该使用接收器操作特性曲线(ROC曲线),而应该在高度不平衡的情况下优先使用精确率/召回率曲线
如果你看定义,你会发现AUC和F1-score都优化了与被标记为“正例”的样本实际上是真正的正例的比例一起的某些东西。
这个“某些东西”分别是:
当你拥有高度不平衡或偏斜的分类时,这个差异变得重要:例如,真负样例会比真正正例多很多。
假设您正在查看来自普通人群的数据,以查找患有罕见疾病的人。负面人数比正面人数多得多,尝试同时优化你在正样本和负样本上的表现,使用AUC并不是最优选择。你希望尽可能地让正样本包含所有的正例,而不想让它过大,因为会有较高的假阳性率。因此,在这种情况下,你使用F1-score。
相反地,如果两个类在数据集中各占50%,或者两个类的比例都很大,并且您关心同等识别每个类的表现,则应该使用AUC,它优化了正类和负类,以达到更好的性能。
我想在这里加入我的两分钱:
AUC对样本进行了隐式加权,而F1没有。
在我上一个使用案例中,比较药物对患者的有效性很容易了解哪些药物通常较强,哪些药物较弱。重点是是否能够针对异常值(弱药物的少数阳性结果或强药物的少数阴性结果)进行研究。为了回答这个问题,你需要使用F1来具体衡量异常值,而AUC则不需要。