我正在使用XGBoost训练BDT模型,对22个特征进行二元分类。我有1800万个样本(60%用于训练,40%用于测试)。
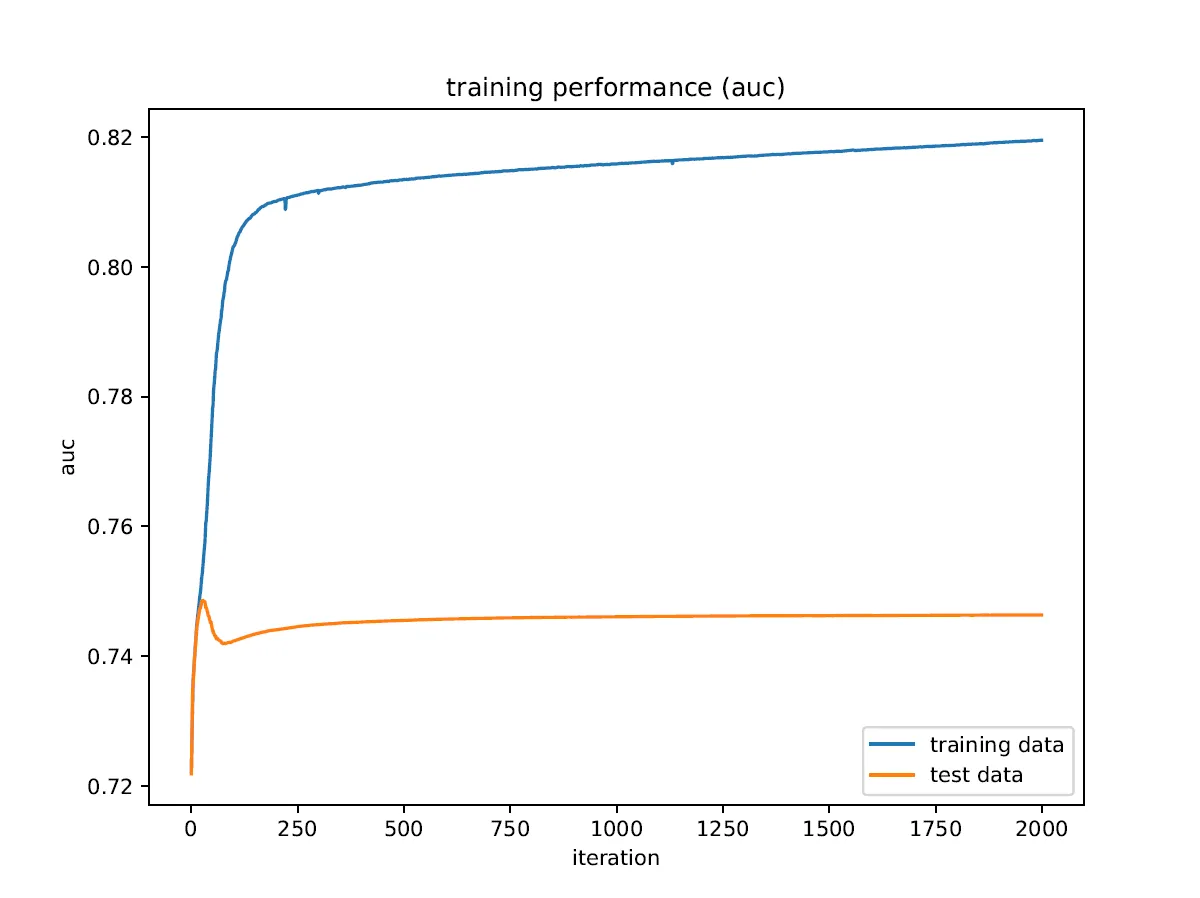
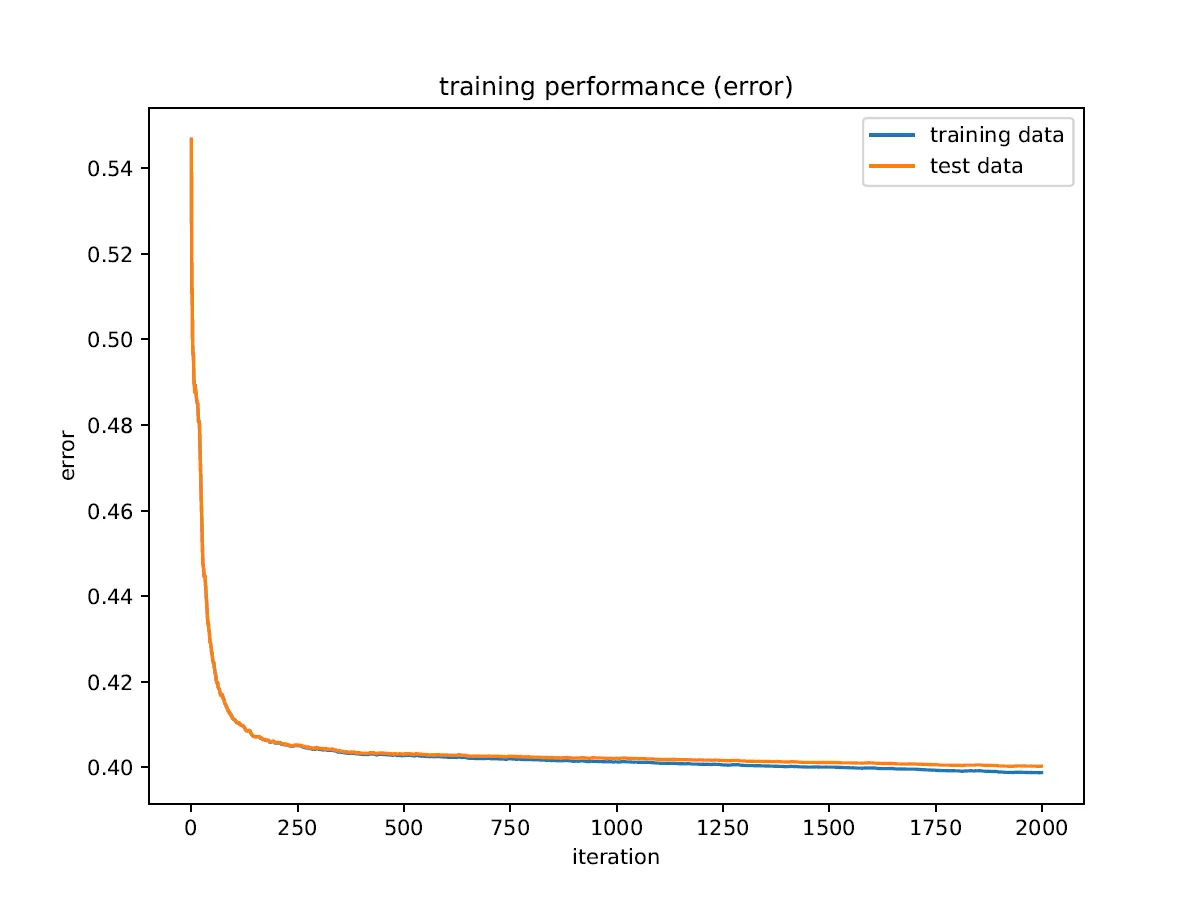
在训练过程中,我得到的ROC AUC值与最终结果不符,我不明白为什么会出现这种情况。此外,ROC AUC指标表现出比其他任何指标更多的过度拟合,并且在测试数据上似乎有一个最大值。
是否有人之前遇到过类似的问题,或者有任何想法可以找出我的模型存在的问题,或者如何找出问题所在?
我的代码核心内容:
params = {
"model_params": {
"n_estimators": 2000,
"max_depth": 4,
"learning_rate": 0.1,
"scale_pos_weight": 11.986832275943744,
"objective": "binary:logistic",
"tree_method": "hist"
},
"train_params": {
"eval_metric": [
"logloss",
"error",
"auc",
"aucpr",
"map"
]
}
}
model = xgb.XGBClassifier(**params["model_params"], use_label_encoder=False)
model.fit(X_train, y_train,
eval_set=[(X_train, y_train), (X_test, y_test)],
**params["train_params"])
train_history = model.evals_result()
...
plt.plot(iterations, train_history["validation_0"]["auc"], label="training data")
plt.plot(iterations, train_history["validation_1"]["auc"], label="test data")
...
y_pred_proba_train = model.predict_proba(X_train)
y_pred_proba_test = model.predict_proba(X_test)
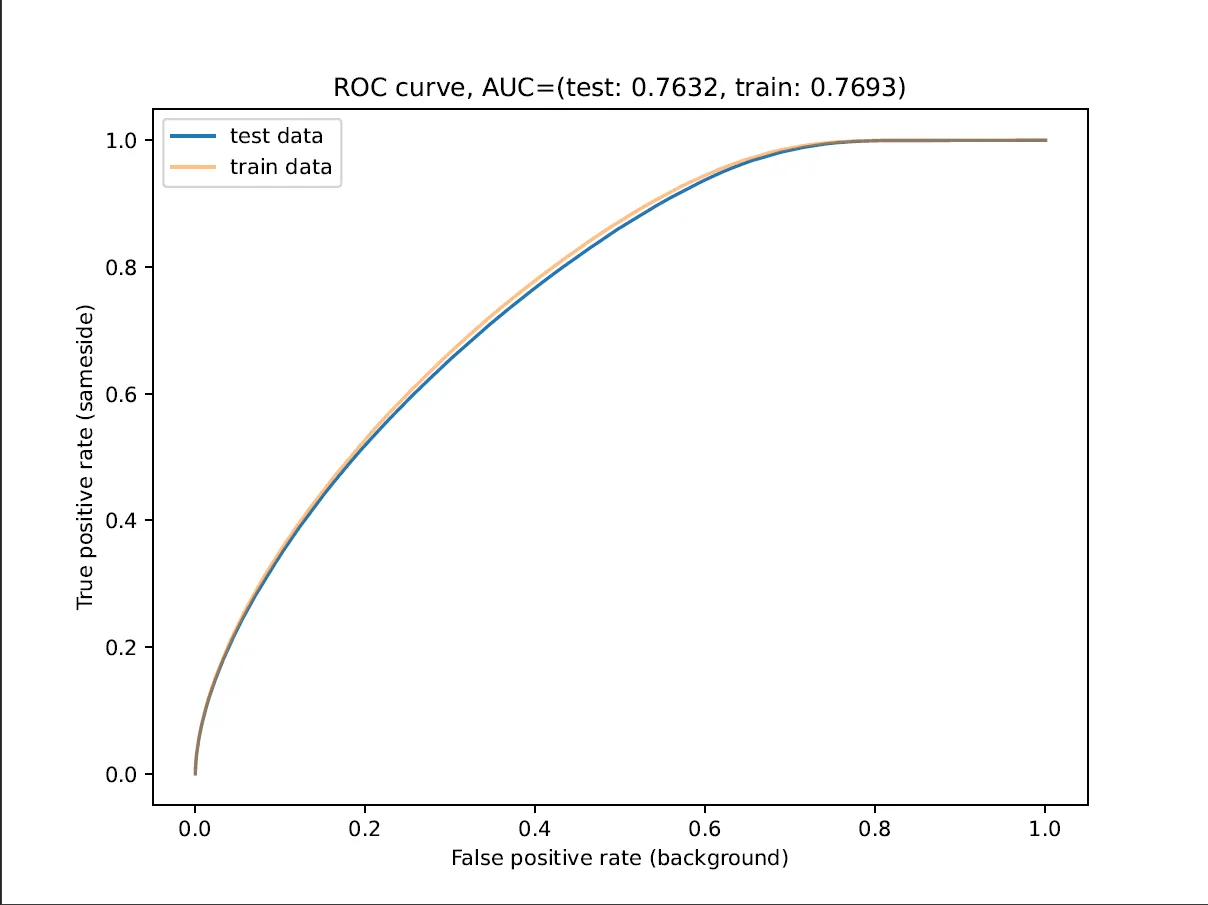
fpr_test, tpr_test, _ = sklearn.metrics.roc_curve(y_test, y_pred_proba_test[:, 1])
fpr_train, tpr_train, _ = sklearn.metrics.roc_curve(y_train, y_pred_proba_train[:, 1])
auc_test = sklearn.metrics.auc(fpr_test, tpr_test)
auc_train = sklearn.metrics.auc(fpr_train, tpr_train)
...
plt.title(f"ROC curve, AUC=(test: {auc_test:.4f}, train: {auc_train:.4f})")
plt.plot(fpr_test, tpr_test, label="test data")
plt.plot(fpr_train, tpr_train, label="train data")
...

scikit-learn默认采用宏平均AUC,而我不确定xgboost采用什么方法,但我猜测它采用微平均。你的数据集是否不平衡?这可能是原因,特别是如果你的测试集没有分层。 - eschibliroc_curve+auc,得到的结果与使用roc_auc_score和macro、weighted或None得到的结果相同。然而,使用micro计算的roc_auc_score在训练和测试数据上得到了较低的分数,为0.71。我不认为这是正确的,但这是一个有趣的观察!samples计算起来需要太长时间。 - Nico G.sklearn.model_selection.train_test_split进行分层抽样。 - Nico G.