使用包含各种特征和回归目标(称为 qval)的数据集训练了一个 XGBoost 回归器。该值 qval 介于 0 和 1 之间,应具有以下分布: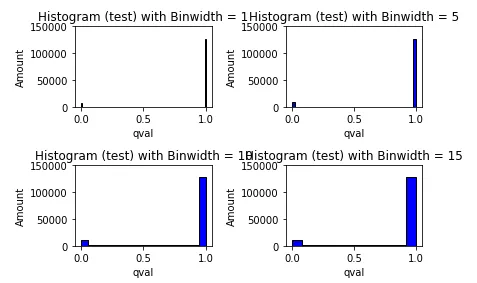 到目前为止,一切都很好。但是,当我使用 xgb.save_model() 保存模型并使用 xgb.load_model() 重新加载它以在另一个数据集上预测此 qval 时,预测的 qval 超出了 [0,1] 边界,如下所示:
到目前为止,一切都很好。但是,当我使用 xgb.save_model() 保存模型并使用 xgb.load_model() 重新加载它以在另一个数据集上预测此 qval 时,预测的 qval 超出了 [0,1] 边界,如下所示: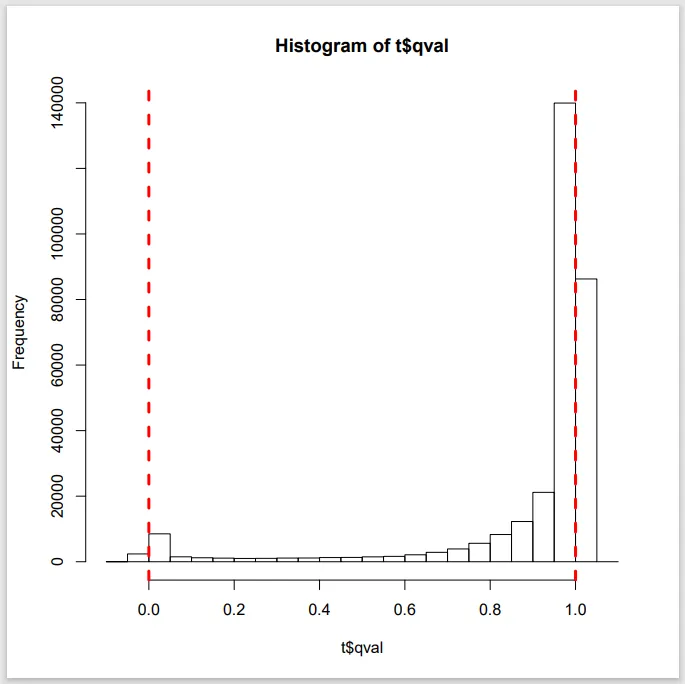 请问是否可以解释一下这种情况是否正常,如果正常,为什么会发生这种情况?从我的角度来看,可能只是“方程式”(此处使用非常糟糕的词)用于计算 qval 的某些数据进行了训练,权重实际上并没有考虑 [0,1] 边界。因此,在将这些权重应用于新数据时,结果超出了边界,但不是完全确定。
请问是否可以解释一下这种情况是否正常,如果正常,为什么会发生这种情况?从我的角度来看,可能只是“方程式”(此处使用非常糟糕的词)用于计算 qval 的某些数据进行了训练,权重实际上并没有考虑 [0,1] 边界。因此,在将这些权重应用于新数据时,结果超出了边界,但不是完全确定。
到目前为止,一切都很好。但是,当我使用 xgb.save_model() 保存模型并使用 xgb.load_model() 重新加载它以在另一个数据集上预测此 qval 时,预测的 qval 超出了 [0,1] 边界,如下所示:
请问是否可以解释一下这种情况是否正常,如果正常,为什么会发生这种情况?从我的角度来看,可能只是“方程式”(此处使用非常糟糕的词)用于计算 qval 的某些数据进行了训练,权重实际上并没有考虑 [0,1] 边界。因此,在将这些权重应用于新数据时,结果超出了边界,但不是完全确定。