我是一名有用的助手,可以为您翻译文本。
我已经训练了一个二元分类器,但我认为我的ROC曲线不正确。 这是包含标签的向量:
和第二个向量是得分向量
当我绘制ROC曲线时,我得到了以下结果:
我已经训练了一个二元分类器,但我认为我的ROC曲线不正确。 这是包含标签的向量:
y_true= [0, 1, 1, 1, 0, 1, 0, 1, 0]
和第二个向量是得分向量
y_score= [
0.43031937, 0.09115553, 0.00650781, 0.02242869, 0.38608587,
0.09407699, 0.40521139, 0.08062053, 0.37445426
]
当我绘制ROC曲线时,我得到了以下结果:
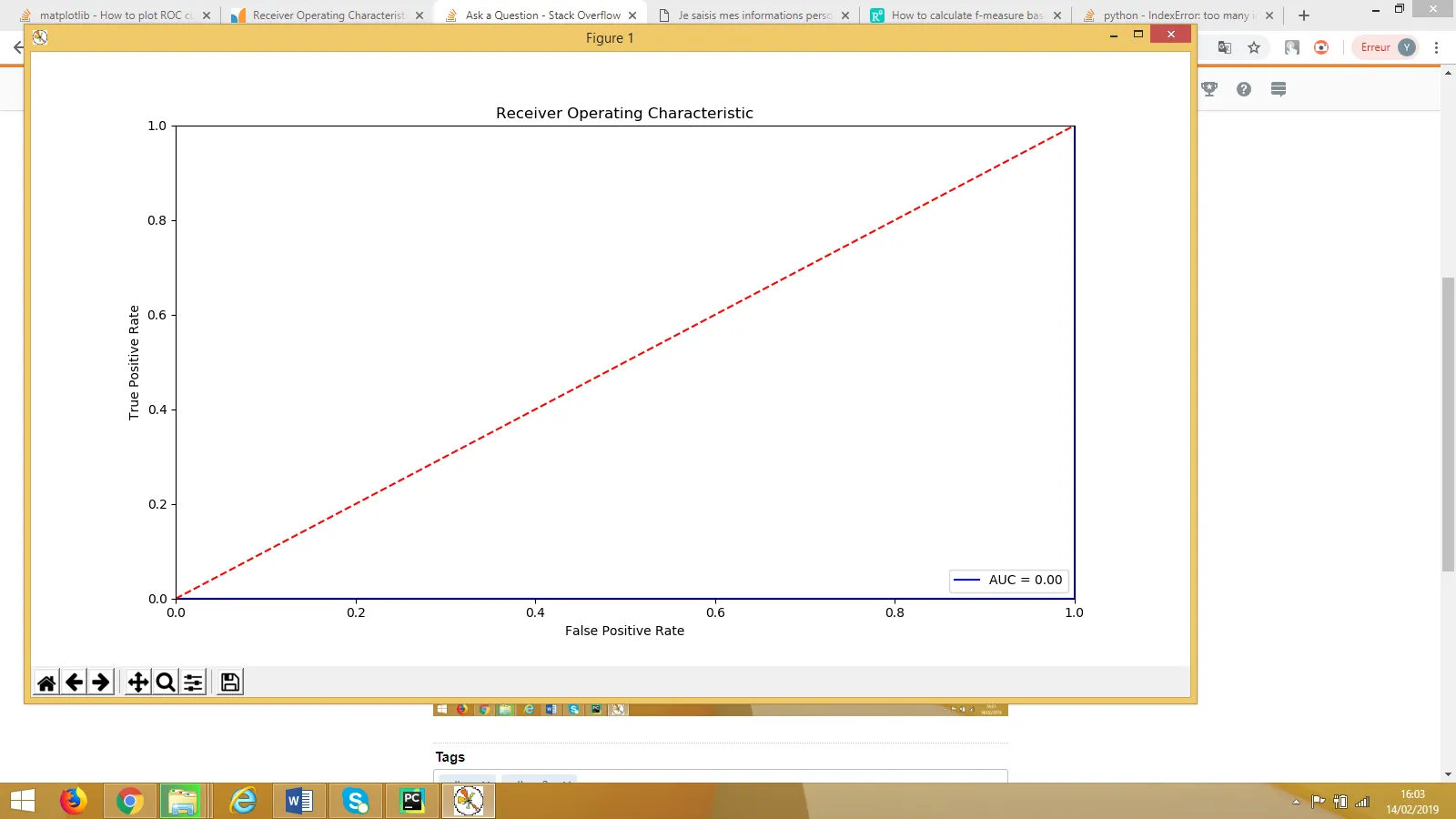
我认为代码是正确的,但我不明白为什么会得到这个曲线以及为什么tpr、fpr和threshold列表的长度为4。为什么我的AUC等于零?
fpr [0. 0.25 1. 1. ]
tpr [0. 0. 0. 1.]
thershold [1.43031937 0.43031937 0.37445426 0.00650781]
我的代码:
import sklearn.metrics as metrics
fpr, tpr, threshold = metrics.roc_curve(y_true, y_score)
roc_auc = metrics.auc(fpr, tpr)
# method I: plt
import matplotlib.pyplot as plt
plt.title('Receiver Operating Characteristic')
plt.plot(fpr, tpr, 'b', label = 'AUC = %0.2f' % roc_auc)
plt.legend(loc = 'lower right')
plt.plot([0, 1], [0, 1],'r--')
plt.xlim([0, 1])
plt.ylim([0, 1])
plt.ylabel('True Positive Rate')
plt.xlabel('False Positive Rate')
plt.show()