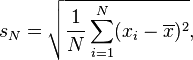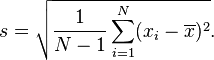我试图为这个问题编写一个解决方案,通过提供一种不同的手动方式来计算均值和标准差。
我按照问题描述创建了数据帧。
我使用
我按照问题描述创建了数据帧。
a= ["Apple","Banana","Cherry","Apple"]
b= [3,4,7,3]
c= [5,4,1,4]
d= [7,8,3,7]
import pandas as pd
df = pd.DataFrame(index=range(4), columns=list("ABCD"))
df["A"]=a
df["B"]=b
df["C"]=c
df["D"]=d
接着,我创建了一个去重的A列表。然后,我遍历了这些项目,每次分组并计算出解决方案。
import numpy as np
l= list(set(df.A))
df.groupby('A', as_index=False)
listMean=[0]*len(df.C)
listSTD=[0]*len(df.C)
for x in l:
s= np.mean(df[df['A']==x].C.values)
z= [index for index, item in enumerate(df['A'].values) if x==item ]
for i in z:
listMean[i]=s
for x in l:
s= np.std(df[df['A']==x].C.values)
z= [index for index, item in enumerate(df['A'].values) if x==item ]
for i in z:
listSTD[i]=s
df['C']= listMean
df['E']= listSTD
print df
我使用
describe()按"A"分组计算平均值和标准差。print df.groupby('A').describe()
我已经测试了建议的解决方案:
result = df.groupby(['a'], as_index=False).agg(
{'c':['mean','std'],'b':'first', 'd':'first'})
我注意到在计算“E”标准差时得到了不同的结果,我很好奇,我错过了什么?