使用pandas 0.19.0。以下代码将重现该问题。
当应用于Series或DataFrame的函数返回Series时,Pandas会自动将其转换为DataFrame。但是,当应用于分组时,行为为什么不同呢?
我正在寻找一个能得到所需输出的答案。如果能解释
In [1]: import pandas as pd
import numpy as np
In [2]: df = pd.DataFrame({'c1' : list('AAABBBCCC'),
'c2' : list('abcdefghi'),
'c3' : np.random.randn(9),
'c4' : np.arange(9)})
df
Out[2]: c1 c2 c3 c4
0 A a 0.819618 0
1 A b 1.764327 1
2 A c -0.539010 2
3 B d 1.430614 3
4 B e -1.711859 4
5 B f 1.002522 5
6 C g 2.257341 6
7 C h 1.338807 7
8 C i -0.458534 8
In [3]: def myfun(s):
"""Function does practically nothing"""
req = s.values
return pd.Series({'mean' : np.mean(req),
'std' : np.std(req),
'foo' : 'bar'})
In [4]: res = df.groupby(['c1', 'c2'])['c3'].apply(myfun)
res.head(10)
Out[4]: c1 c2
A a foo bar
mean 0.819618
std 0
b foo bar
mean 1.76433
std 0
c foo bar
mean -0.53901
std 0
B d foo bar
当然,我期望这个:
Out[4]: foo mean std
c1 c2
A a bar 0.819618 0
b bar 1.76433 0
c bar -0.53901 0
B d bar 1.43061 0
当应用于Series或DataFrame的函数返回Series时,Pandas会自动将其转换为DataFrame。但是,当应用于分组时,行为为什么不同呢?
我正在寻找一个能得到所需输出的答案。如果能解释
pandas.Series.apply或pandas.DataFrame.apply和pandas.core.groupby.GroupBy.apply之间行为差异的奖励分。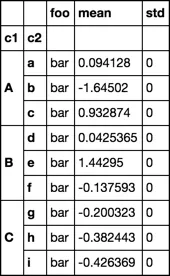
res = df.groupby(['c1', 'c2'])['c3'].apply(lambda x: pd.DataFrame({'mean' : [np.mean(x)], 'std' : [np.std(x)], 'foo' : 'bar'}))那么它将按预期工作 - EdChum