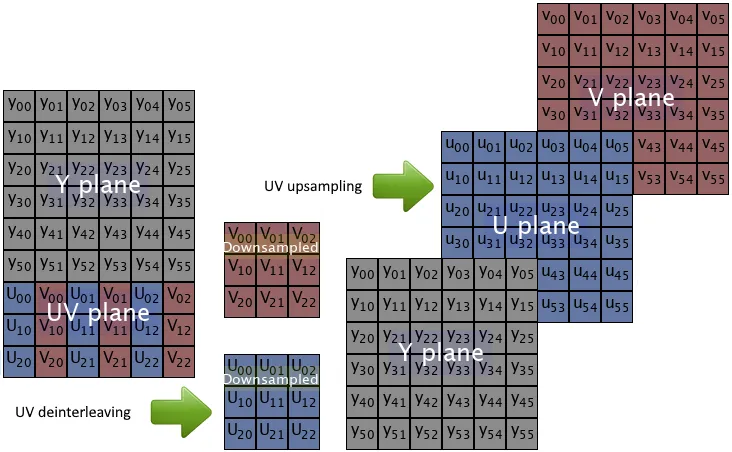
我有一段代码,可以将从nv12格式转换为yuv444格式的图像
for h in range(self.img_shape[0]):
# centralize yuv 444 data for inference framework
for w in range(self.img_shape[1]):
yuv444_res[h][w][0] = (nv12_y_data[h * self.img_shape[1] +w]).astype(np.int8)
yuv444_res[h][w][1] = (nv12_u_data[int(h / 2) * int(self.img_shape[1] / 2) +int(w / 2)]).astype(np.int8)
yuv444_res[h][w][2] = (nv12_v_data[int(h / 2) * int(self.img_shape[1] / 2) +int(w / 2)]).astype(np.int8)
由于在Python中,for循环非常慢,比NumPy慢得多。所以我想知道是否可以通过NumPy计算来完成此转换。
2021年6月15日更新:
我从这个页面外部链接获取了这段使用花式索引的代码:
yuv444 = np.empty([self.height, self.width, 3], dtype=np.uint8)
yuv444[:, :, 0] = nv12_data[:self.width * self.height].reshape(
self.height, self.width)
u = nv12_data[self.width * self.height::2].reshape(
self.height // 2, self.width // 2)
yuv444[:, :, 1] = Image.fromarray(u).resize((self.width, self.height))
v = nv12_data[self.width * self.height + 1::2].reshape(
self.height // 2, self.width // 2)
yuv444[:, :, 2] = Image.fromarray(v).resize((self.width, self.height))
data[0] = yuv444.astype(np.int8)
如果使用PIL替换弃用的imresize,则代码与旧代码完全匹配100%。
更新于2021年06月19日:
经过对Rotem所给答案的仔细审查,我意识到他的方法更快。
#nv12_data is reshaped to one dimension
y = nv12_data[:self.width * self.height].reshape(
self.height, self.width)
shrunk_u = nv12_data[self.width * self.height::2].reshape(
self.height // 2, self.width // 2)
shrunk_v = nv12_data[self.width * self.height + 1::2].reshape(
self.height // 2, self.width // 2)
u = cv2.resize(shrunk_u, (self.width, self.height),
interpolation=cv2.INTER_NEAREST)
v = cv2.resize(shrunk_v, (self.width, self.height),
interpolation=cv2.INTER_NEAREST)
yuv444 = np.dstack((y, u, v))
另外,我对处理1000张图片所需的时间进行了比较。结果表明,cv reshape 更快,且保证相同的结果。
cv time: 4.417593002319336, pil time: 5.395732164382935
2021年6月25日更新:
Pillow的resize函数在不同版本中具有不同的默认重采样参数值。
5.1.0版本:
def resize(self, size, resample=NEAREST, box=None):
8.1.0:
def resize(self, size, resample=BICUBIC, box=None, reducing_gap=None):
最好明确指定使用的重采样策略。