我使用并熟悉 cv2,今天我尝试了一下 skimage。
我试着用 skimage 和 cv2 读取一张图片。它们都能完美地读取图片,但是当我通过不同的库(skimage 和 cv2)绘制图像的直方图时,直方图显示出了显著的差异。
有人可以帮忙解释一下这两个直方图之间的差异吗?
我的代码:
import cv2
import skimage.io as sk
import numpy as np
import matplotlib.pyplot as plt
path = '../../img/lenna.png'
img1 = sk.imread(path, True)
img2 = cv2.imread(path, cv2.IMREAD_GRAYSCALE)
print(img1.shape)
print(img2.shape)
plt.subplot(2, 2, 1)
plt.imshow(img1, cmap='gray')
plt.title('skimage read')
plt.xticks([])
plt.yticks([])
plt.subplot(2, 2, 2)
plt.imshow(img2, cmap='gray')
plt.title('cv2 read')
plt.xticks([])
plt.yticks([])
plt.subplot(2, 2, 3)
h = np.histogram(img1, 100)
plt.plot(h[0])
plt.title('skimage read histogram')
plt.subplot(2, 2, 4)
h = np.histogram(img2, 100)
plt.plot(h[0])
plt.title('cv2 read histogram')
plt.show()
文本输出:
(512, 512) (512, 512)
输出:
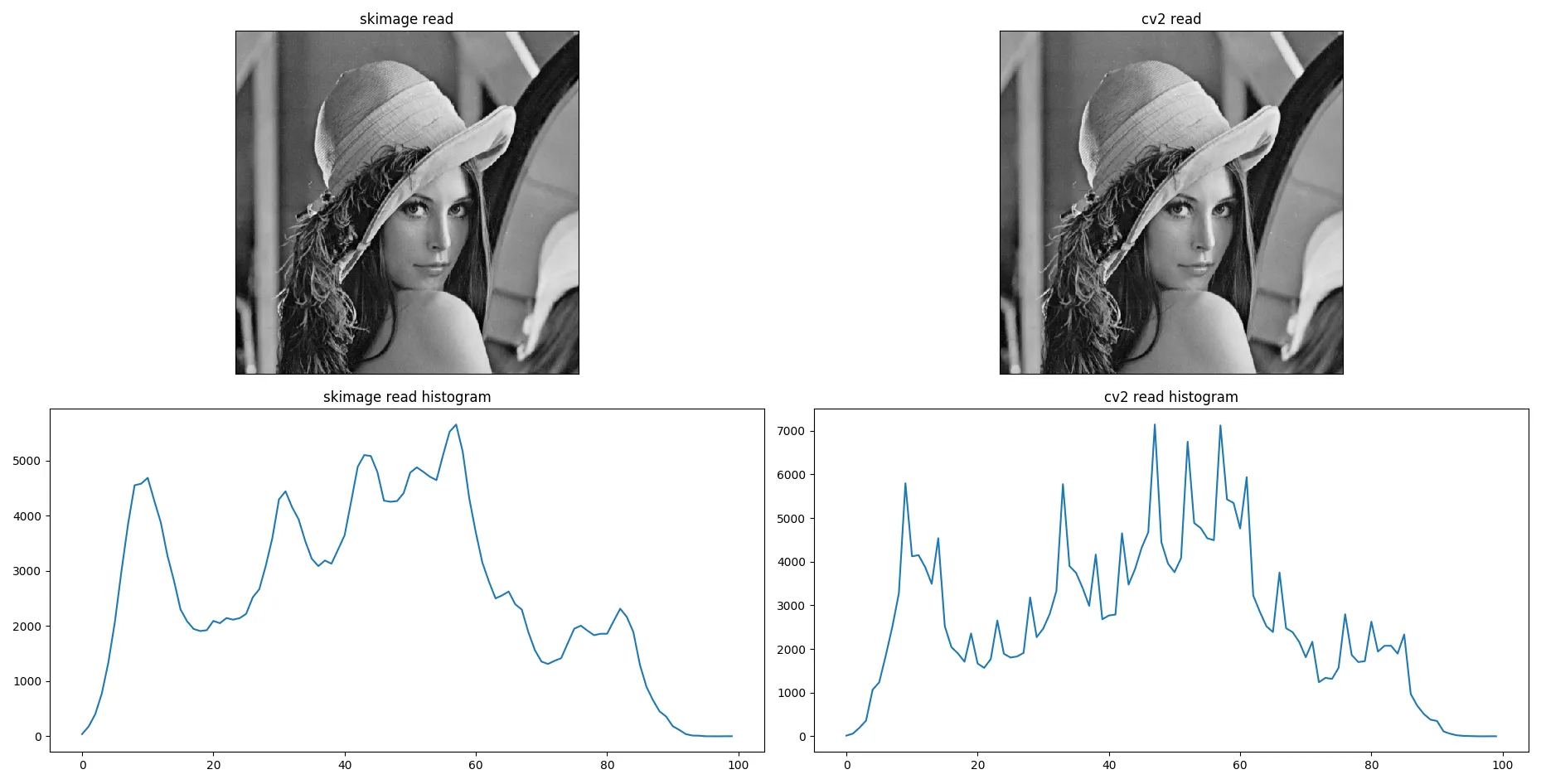
编辑:
这是输入图像:


np.mean()和np.std()值,以便我们可以确定差异是在加载和灰度转换中还是在直方图生成和显示中?此外,如果您能分享您使用的实际 Lena 图像,那将会很有帮助。 - Mark Setchellnp.mean和np.std,它们告诉了很多。skimage mean: 0.4578778306070963 skimage std: 0.19380367354500247 cv2 mean: 123.54518127441406 cv2 std: 47.853738824592234- Arafat Hasan