我有一个包含全部分类变量的数据集,我想一次性为所有变量生成频率计数。使用鸢尾花数据集函数
具有分类变量的样本数据集:
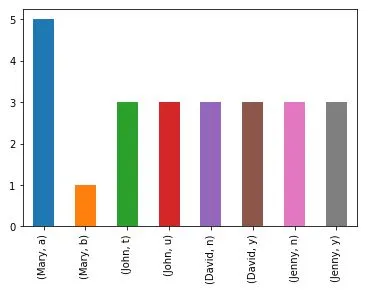
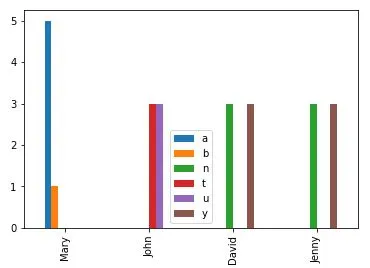
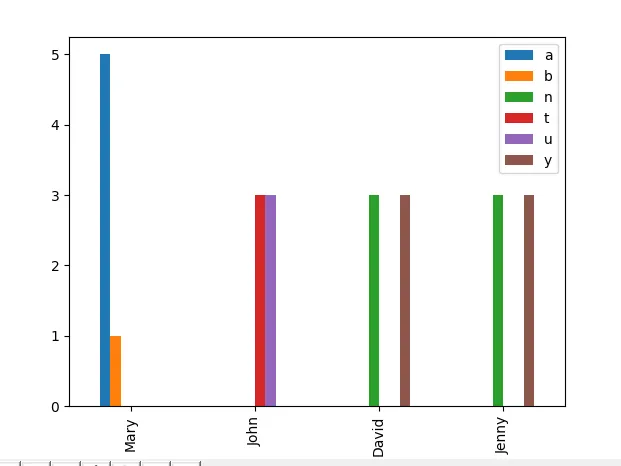
df['class'].value_counts()只能计算一个变量。为了分析仅由Pandas提取的分类变量组成的数据集中的所有变量,我考虑仅提取第一行并将其放入for循环中。要从csv文件中提取第一行,我们使用data = pd.DataFrame(data)将csv转换为数据框。但是,data[0]会生成错误。生产所有变量的频率分析或条形图的最有效方法是什么?具有分类变量的样本数据集:
Mary John David Jenny
a t y n
a t n y
a u y y
a u n y
a u n n
b t y n