我正在学习numpy,其中有一个叫做“strides”的主题。我理解这个主题的概念,但不知道它是如何工作的。我在网上没有找到任何有用的信息,有谁能用通俗易懂的语言帮我了解一下吗?
3个回答
122
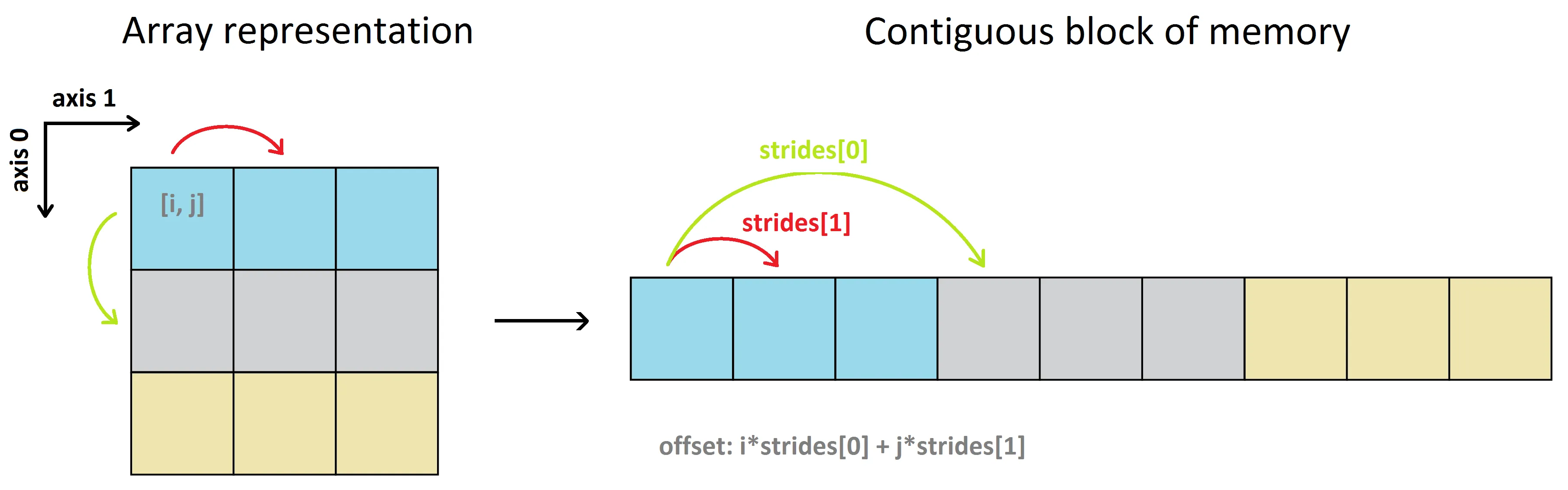
一个numpy数组的实际数据存储在一个称为数据缓冲区的同质连续内存块中。更多信息请参见NumPy internals。
使用(默认的)行优先顺序,一个二维数组看起来像这样:
所以,从
然而,要从
这就是为什么。
这是另一个例子,展示了在水平方向(轴1)的步长
这里的
最后但并非最不重要的一点是,NumPy允许使用修改步幅和形状的选项创建现有数组的视图,参见stride tricks。例如:
>>> a = np.arange(1,10).reshape(3,3)
>>> a
array([[1, 2, 3],
[4, 5, 6],
[7, 8, 9]])
这个二维数组有两个方向,轴0(沿行从上往下垂直运行),和轴1(沿列从左往右水平运行),每个项的大小为:
>>> a.itemsize # in bytes
4
所以,从
a[0, 0] -> a[0, 1](沿着第0行水平移动,从第0列到第1列)在数据缓冲区中的字节步长为4。对于a[0, 1] -> a[0, 2]、a[1, 0] -> a[1, 1]等也是如此。这意味着水平方向(轴-1)的步幅数为4个字节。然而,要从
a[0, 0] -> a[1, 0](沿着第0列垂直移动,从第0行到第1行),需要先遍历所有剩余的第0行项目才能到达第1行,然后通过第1行移动到项目 a[1, 0],即 a[0, 0] -> a[0, 1] -> a[0, 2] -> a[1, 0]。因此,垂直方向(轴-0)的步幅数为3*4 = 12个字节。请注意,从 a[0, 2] -> a[1, 0],以及一般地从第i行的最后一个项目到第(i+1)行的第一个项目,也是4个字节,因为数组 a 是按行主序存储的。这就是为什么。
>>> a.strides # (strides[0], strides[1])
(12, 4)
这是另一个例子,展示了在水平方向(轴1)的步长
strides[1]不一定等于项大小的2D数组(例如列优先顺序的数组)。>>> b = np.array([[1, 4, 7],
[2, 5, 8],
[3, 6, 9]]).T
>>> b
array([[1, 2, 3],
[4, 5, 6],
[7, 8, 9]])
>>> b.strides
(4, 12)
这里的
strides[1]是项大小的倍数。尽管数组b看起来与数组a相同,但它们是不同的数组:在内部,b被存储为|1|4|7|2|5|8|3|6|9|(因为转置不影响数据缓冲区,只交换步长和形状),而a则为|1|2|3|4|5|6|7|8|9|。使它们看起来相似的是不同的步幅。也就是说,b[0, 0] -> b[0, 1]的字节步长为3*4=12字节,b[0, 0] -> b[1, 0]的字节步长为4字节,而a[0, 0] -> a[0, 1]的字节步长为4字节,a[0, 0] -> a[1, 0]的字节步长为12字节。最后但并非最不重要的一点是,NumPy允许使用修改步幅和形状的选项创建现有数组的视图,参见stride tricks。例如:
>>> np.lib.stride_tricks.as_strided(a, shape=a.shape[::-1], strides=a.strides[::-1])
array([[1, 4, 7],
[2, 5, 8],
[3, 6, 9]])
这相当于对数组 a 进行转置。
让我简单补充一下,但不会深入细节,我们甚至可以定义非项大小倍数的步长。以下是一个示例:
>>> a = np.lib.stride_tricks.as_strided(np.array([1, 512, 0, 3], dtype=np.int16),
shape=(3,), strides=(3,))
>>> a
array([1, 2, 3], dtype=int16)
>>> a.strides[0]
3
>>> a.itemsize
2
- Andreas K.
10
1你虽然暗示了这一点,但我还是要明确地说一下:不论数组有多少维,它都必须以某种方式存储在内存中,你可以将其视为内存中的一个字节一维向量。步幅帮助将 n 维映射到一维。 - Bas Swinckels
1谢谢您的评论。我会尝试将其添加到我的答案中。 - Andreas K.
3谢谢你,AndyK。你的解释非常好。我希望文档也能以这种漂亮的方式完成。 - Atif
@AndyK,现在好多了,回答非常好。有些我自己的免费网络积分,请多多关注。 - Bas Swinckels
1我对这行代码有些困惑:“尽管数组b看起来与数组a相同,但它是一个不同的数组:在内部,b被存储为|1|4|7|2|5|8|3|6|9|(因为转置不会影响数据缓冲区,只会交换步幅和形状),而a则为|1|2|3|4|5|6|7|8|9|。”如果转置不影响数据缓冲区,那么b不应该也在内部存储为|1|2|3|4|5|6|7|8|9|吗?或者你是说,当创建副本时,会创建一个新的缓冲区,其顺序选择反映内容而不是最小化更改? - Alan
显示剩余5条评论
24
仅添加至 @AndyK 的出色 answer,我从Numpy MedKit中了解了关于numpy步幅的知识。其中他们展示了一个如下所示的问题的使用:
给定输入:
为了实现这一点,我们需要了解以下术语:
{{shape}} - 沿着每个轴的数组维度。
{{strides}} - 必须跳过的内存字节数,以沿着某个维度前进到下一个项。
现在,如果我们看一下{{预期输出}}:
我们需要操作数组的形状和步幅。输出形状必须为(3, 2, 5),即3个项目,每个项目包含两行(m == 2),每行有5个元素。
步幅需要从(20, 4)更改为(20, 20, 4)。新输出数组中的每个项目都从一个新行开始,每行由20个字节组成(4个字节的每个元素5个),每个元素占用4个字节(int32)。
所以:
我经常使用这种方法,而不是numpy.hstack或numpy.vstack,相信我,在计算上它会快得多。
注意:
当使用非常大的数组时,计算精确的步幅并不是那么容易的。我通常会创建一个所需形状的
希望对你有所帮助!
x = np.arange(20).reshape([4, 5])
>>> x
array([[ 0, 1, 2, 3, 4],
[ 5, 6, 7, 8, 9],
[10, 11, 12, 13, 14],
[15, 16, 17, 18, 19]])
预期输出:
array([[[ 0, 1, 2, 3, 4],
[ 5, 6, 7, 8, 9]],
[[ 5, 6, 7, 8, 9],
[ 10, 11, 12, 13, 14]],
[[ 10, 11, 12, 13, 14],
[ 15, 16, 17, 18, 19]]])
为了实现这一点,我们需要了解以下术语:
{{shape}} - 沿着每个轴的数组维度。
{{strides}} - 必须跳过的内存字节数,以沿着某个维度前进到下一个项。
>>> x.strides
(20, 4)
>>> np.int32().itemsize
4
现在,如果我们看一下{{预期输出}}:
array([[[ 0, 1, 2, 3, 4],
[ 5, 6, 7, 8, 9]],
[[ 5, 6, 7, 8, 9],
[ 10, 11, 12, 13, 14]],
[[ 10, 11, 12, 13, 14],
[ 15, 16, 17, 18, 19]]])
我们需要操作数组的形状和步幅。输出形状必须为(3, 2, 5),即3个项目,每个项目包含两行(m == 2),每行有5个元素。
步幅需要从(20, 4)更改为(20, 20, 4)。新输出数组中的每个项目都从一个新行开始,每行由20个字节组成(4个字节的每个元素5个),每个元素占用4个字节(int32)。
所以:
>>> from numpy.lib import stride_tricks
>>> stride_tricks.as_strided(x, shape=(3, 2, 5),
strides=(20, 20, 4))
...
array([[[ 0, 1, 2, 3, 4],
[ 5, 6, 7, 8, 9]],
[[ 5, 6, 7, 8, 9],
[ 10, 11, 12, 13, 14]],
[[ 10, 11, 12, 13, 14],
[ 15, 16, 17, 18, 19]]])
另一个选择可能是:
>>> d = dict(x.__array_interface__)
>>> d['shape'] = (3, 2, 5)
>>> s['strides'] = (20, 20, 4)
>>> class Arr:
... __array_interface__ = d
... base = x
>>> np.array(Arr())
array([[[ 0, 1, 2, 3, 4],
[ 5, 6, 7, 8, 9]],
[[ 5, 6, 7, 8, 9],
[ 10, 11, 12, 13, 14]],
[[ 10, 11, 12, 13, 14],
[ 15, 16, 17, 18, 19]]])
我经常使用这种方法,而不是numpy.hstack或numpy.vstack,相信我,在计算上它会快得多。
注意:
当使用非常大的数组时,计算精确的步幅并不是那么容易的。我通常会创建一个所需形状的
numpy.zeros数组,并使用array.strides获取步幅,并在函数stride_tricks.as_strided中使用它。希望对你有所帮助!
- Rick M.
8
我根据@Rick M.提供的代码修改了它以适应我的问题,即对任何形状的numpy数组进行移动窗口切片。以下是代码:
def sliding_window_slicing(a, no_items, item_type=0):
"""This method perfoms sliding window slicing of numpy arrays
Parameters
----------
a : numpy
An array to be slided in subarrays
no_items : int
Number of sliced arrays or elements in sliced arrays
item_type: int
Indicates if no_items is number of sliced arrays (item_type=0) or
number of elements in sliced array (item_type=1), by default 0
Return
------
numpy
Sliced numpy array
"""
if item_type == 0:
no_slices = no_items
no_elements = len(a) + 1 - no_slices
if no_elements <=0:
raise ValueError('Sliding slicing not possible, no_items is larger than ' + str(len(a)))
else:
no_elements = no_items
no_slices = len(a) - no_elements + 1
if no_slices <=0:
raise ValueError('Sliding slicing not possible, no_items is larger than ' + str(len(a)))
subarray_shape = a.shape[1:]
shape_cfg = (no_slices, no_elements) + subarray_shape
strides_cfg = (a.strides[0],) + a.strides
as_strided = np.lib.stride_tricks.as_strided #shorthand
return as_strided(a, shape=shape_cfg, strides=strides_cfg)
这种方法可以自动计算步长(strides),并且适用于numpy数组的任何维度:
1D数组 - 通过切片数量进行切片
In [11]: a
Out[11]: array([0, 1, 2, 3, 4, 5, 6, 7, 8, 9])
In [12]: sliding_window_slicing(a, 5, item_type=0)
Out[12]:
array([[0, 1, 2, 3, 4, 5],
[1, 2, 3, 4, 5, 6],
[2, 3, 4, 5, 6, 7],
[3, 4, 5, 6, 7, 8],
[4, 5, 6, 7, 8, 9]])
1D数组 - 通过每个切片的元素数量进行切片
In [13]: sliding_window_slicing(a, 5, item_type=1)
Out[13]:
array([[0, 1, 2, 3, 4],
[1, 2, 3, 4, 5],
[2, 3, 4, 5, 6],
[3, 4, 5, 6, 7],
[4, 5, 6, 7, 8],
[5, 6, 7, 8, 9]])
二维数组 - 通过切片获取多个数组元素
In [16]: a = np.arange(10).reshape([5,2])
In [17]: a
Out[17]:
array([[0, 1],
[2, 3],
[4, 5],
[6, 7],
[8, 9]])
In [18]: sliding_window_slicing(a, 2, item_type=0)
Out[18]:
array([[[0, 1],
[2, 3],
[4, 5],
[6, 7]],
[[2, 3],
[4, 5],
[6, 7],
[8, 9]]])
2D数组 - 根据每个切片的元素数量进行切片
In [19]: sliding_window_slicing(a, 2, item_type=1)
Out[19]:
array([[[0, 1],
[2, 3]],
[[2, 3],
[4, 5]],
[[4, 5],
[6, 7]],
[[6, 7],
[8, 9]]])
- Nikola V.
网页内容由stack overflow 提供, 点击上面的可以查看英文原文,
原文链接
原文链接