我正在使用 ggplot2movies 库来处理我的数据 movies
请注意,我提到的 MPAA 分级和用户评分是两个不同的概念。如果您不想加载 ggplot2movies 库,这里提供了相关数据的示例:
> head(subset(movies[,c(5,17)], movies$mpaa!=""))
# A tibble: 6 x 2
rating mpaa
<dbl> <chr>
1 5.3 R
2 7.1 PG-13
3 7.2 PG-13
4 4.9 R
5 4.8 PG-13
6 6.7 PG-13
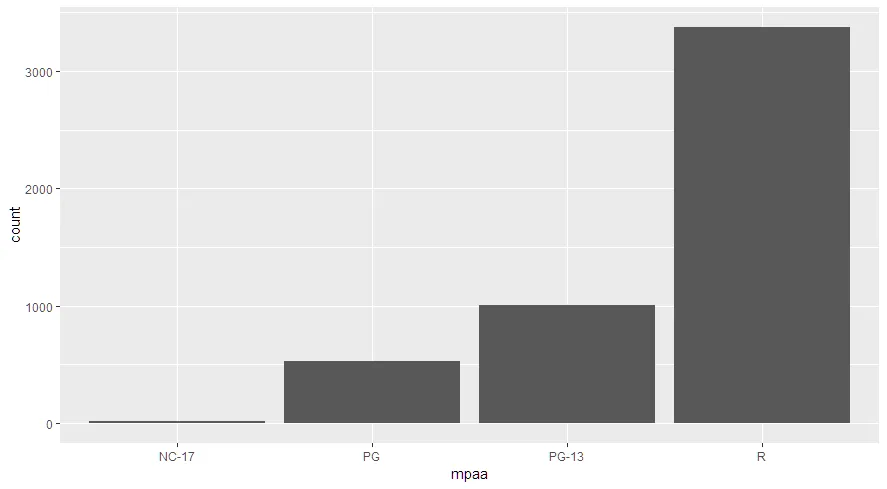
这里我制作了一个条形图,显示具有任何mpaa评级的电影频率:
ggplot(data=subset(movies, movies$mpaa!=""), aes(mpaa)) +
geom_bar()
现在我想根据IMDB用户评分来填充条形图的颜色。 我不想使用factor(rating),因为评分列中有大量不同的值。 然而,当我尝试像将连续填充颜色分配给geom_bar一样使用连续填充时,我得到了相同的图形。
ggplot(data=subset(movies, movies$mpaa!=""), aes(mpaa, fill=rating)) +
geom_bar()+
scale_fill_continuous(low="blue", high="red")
我认为这与我的条形图基于单个变量的频率有关,而不是带有计数列的数据框。我可以创建一个新的包含mpaa类别及其计数的数据框,但我更想知道如何使用原始的
movies数据集和单个ggplot来制作此图。编辑:使用
aes(mpaa,group=rating,fill=rating)会得到一个几乎正确的图表,只是条形和图例被交换了。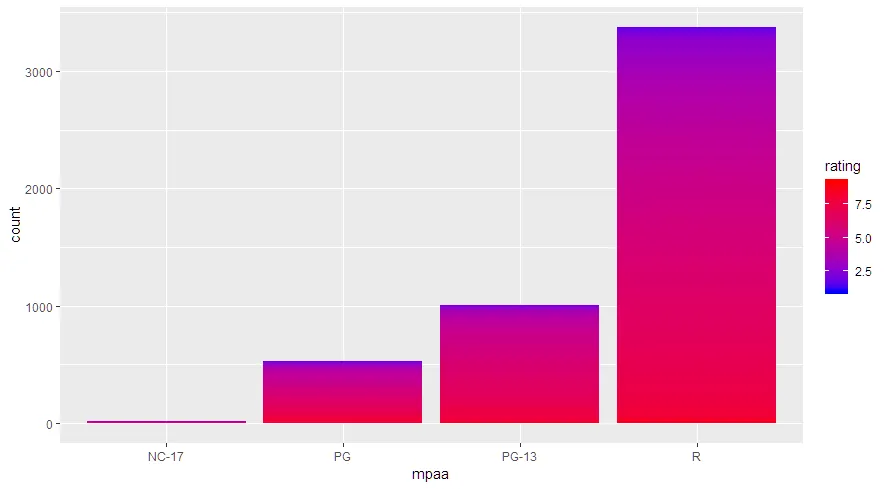
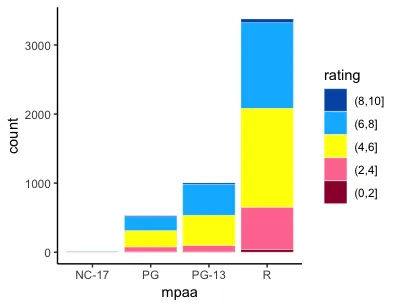
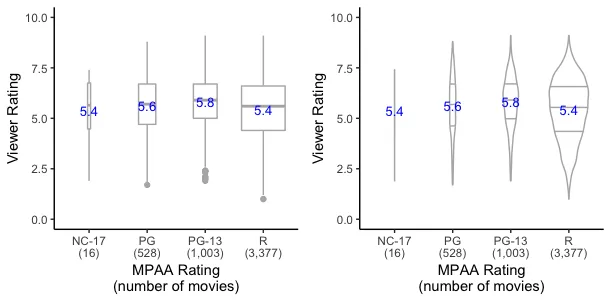
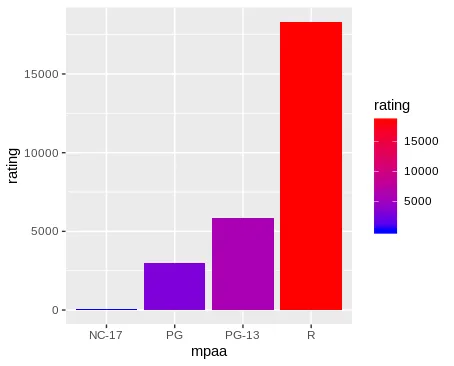
aes(mpaa, group = rating, fill = rating)。 - hrbrmstr