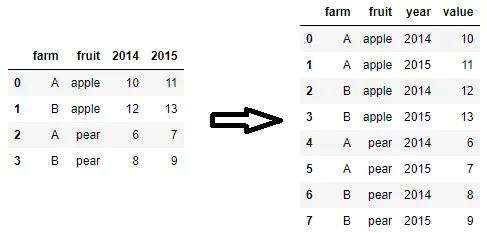
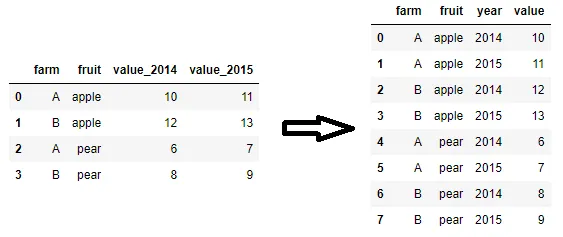
我有一个pandas DataFrame,例如:
df = pd.DataFrame({'farm' : ['A','B','A','B'],
'fruit':['apple','apple','pear','pear'],
'2014':[10,12,6,8],
'2015':[11,13,7,9]})
即:
2014 2015 farm fruit
0 10 11 A apple
1 12 13 B apple
2 6 7 A pear
3 8 9 B pear
如何将它转换为以下格式?
farm fruit value year
0 A apple 10 2014
1 B apple 12 2014
2 A pear 6 2014
3 B pear 8 2014
4 A apple 11 2015
5 B apple 13 2015
6 A pear 7 2015
7 B pear 9 2015
我尝试过 stack 和 unstack 但是无法使其工作。