我正在尝试实现一个向量化的 Numpy 版本的 itertools.combinations,以便我可以使用 @jit(Numba)进行修饰 - 使其更快。(我不确定是否可以完成这个任务)
我正在处理的数据集是一个一维 np.array,目标是获取三元组组合。
x = np.array([1,2,3,4,5])
set(combinations(x, 3))
Result:
{(1, 2, 3),
(1, 2, 4),
(1, 2, 5),
(1, 3, 4),
(1, 3, 5),
(1, 4, 5),
(2, 3, 4),
(2, 3, 5),
(2, 4, 5),
(3, 4, 5)}
我一直在搜索堆栈和其他资源,我确实发现了关于这个主题的很多信息,但是没有任何有用的信息适用于我的用例。
numpy中itertools.combinations的N-D版本
这个线程表明,很可能很难找到比itertools.combinations更快的东西:
itertools.combinations的numba安全版本?
我被要求更具体地说明用例:
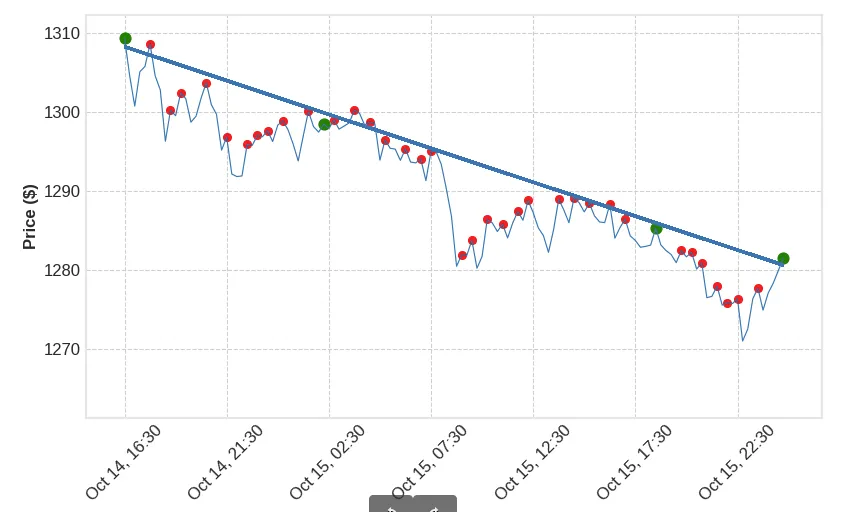
我有一个价格数据 np.array price= ([100,101,102,103,104,105 等等..])
我使用 scipy.signal.argrelmax 找到数组中的所有峰值。(上图中的红点。)
现在我需要获取所有峰值的组合。
然后我将对所有组合运行简单的线性回归,并寻找特定的 r_val 阈值,以验证趋势线。(上图中的绿点)
(选择 3 的组合是因为这样我就知道趋势线有 3 个触点。在我发布的插图中有 4 个触点,所以我会处理 3 或 4 个触点。)
(此外,我使用趋势线上方/下方的积分进行过滤)
我不需要 combi 函数返回一组元组,我编写的简单线性回归算法已经针对 numpy 进行了优化。