我想使用以下C代码进行块矩阵乘法。在这种方法中,大小为BLOCK_SIZE的块被加载到最快的缓存中,以减少计算期间的内存访问。
void bMMikj(double **A , double **B , double ** C , int m, int n , int p , int BLOCK_SIZE){
int i, j , jj, k , kk ;
register double jjTempMin = 0.0 , kkTempMin = 0.0;
for (jj=0; jj<n; jj+= BLOCK_SIZE) {
jjTempMin = min(jj+ BLOCK_SIZE,n);
for (kk=0; kk<n; kk+= BLOCK_SIZE) {
kkTempMin = min(kk+ BLOCK_SIZE,n);
for (i=0; i<n; i++) {
for (k = kk ; k < kkTempMin ; k++) {
for (j=jj; j < jjTempMin; j++) {
C[i][j] += A[i][k] * B[k][j];
}
}
}
}
}
}
我搜索了关于最适合的BLOCK_SIZE值的信息,发现 BLOCK_SIZE <= sqrt(M_fast/3),其中M_fast是L1缓存。
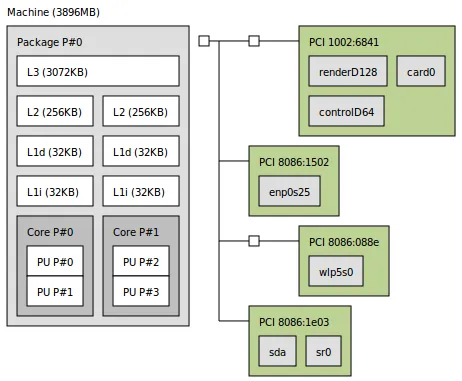
在我的电脑上,我有两个L1缓存,如此处所示,使用lstopo工具可以查看。
 以下是使用启发式方法的示例,从
以下是使用启发式方法的示例,从BLOCK_SIZE为4开始,每次增加8,重复1000次,使用不同的矩阵大小。
BLOCK_SIZE值,这将是最适合的值。下面是测试代码:
int BLOCK_SIZE = 4;
int m , n , p;
m = n = p = 1024; /* This value is also changed
and all the matrices are square, for simplicity
*/
for(int i=0;i< 1000; i++ , BLOCK_SIZE += 8) {
# aClock.start();
test_bMMikj(A , B , C , loc_n , loc_n , loc_n ,BLOCK_SIZE);
# aClock.stop();
}
测试结果每个矩阵大小不同,与公式不符。计算机型号为“Intel® Core™ i5-3320M CPU @ 2.60GHz × 4”,内存为3.8GiB,此处是Intel规格说明。
另外一个问题:
如果我有两个L1缓存,像我在这里看到的那样,我应该将BLOCK_SIZE考虑为其中一个还是两者之和?
lstopo检查 CPU 架构(NUMA 缓存)并加 1。除非您披露编译详细信息,否则没有人能告诉您更多。因此,在物理核心 P#0 上为代码执行定位的线程将无法从属于 P#1 物理核心的 L1d 中的任何数据中受益,因此关于“共享”存储的猜测仅从 L3 缓存开始有效(实际上不超过约 3 MB)。还要始终检查实际的 CPU 缓存关联性、缓存行大小和所有细节,以确定使用缓存预取掩盖 DRAM 访问延迟的机会。 - user3666197